지난 포스팅에서 소개했듯이, 트랜스포머를 이용한 아키텍처는 자연어처리를 넘어 컴퓨터비전의 분야까지 파고들어 좋은 성능을 내고 있다. 트랜스포머를 컴퓨터 비전에 처음 도입한 논문이 바로 이 게시물에서 구현해볼 Vision Transformer(ViT)이다.
이 게시물에서는 PyTorch를 이용해서 Vision Transformer를 직접 구현해보고, 숫자 이미지를 분류하는 데이터셋인 MNIST 데이터셋을 분류할 수 있도록 훈련하는 것을 목표로 한다.
개발환경은 모두 Google Colab을 기준으로 하였다.
라이브러리 세팅
%%capture
!pip install torchinfo torch-lr-finder
우선 필요한 패키지들을 깔아준다. Colab에는 이미 PyTorch 등의 라이브러리들이 설치되어 있지만, 모델 summary를 표시해주는 torchinfo나 learning rate를 추천해주는 torch-lr-finder등을 추가로 설치해주기로 한다. 참고로 예전에는 torchinfo 대신 torchsummary를 더욱 자주 사용했었지만, 한동안 업데이트가 없어 트랜스포머 아키텍처에는 사용할 수 없다고 한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from torchvision import datasets, transforms
설치가 완료되었다면 위와 같이 필요한 라이브러리들을 import해준다.
Encoder 클래스 구현
class Encoder(nn.Module):
def __init__(self, embed_size=768, num_heads=3, dropout=0.1):
super().__init__()
self.ln1 = nn.LayerNorm(embed_size)
self.attention = nn.MultiheadAttention(embed_size, num_heads, dropout, batch_first=True)
self.ln2 = nn.LayerNorm(embed_size)
self.ff = nn.Sequential(
nn.Linear(embed_size, 4 * embed_size),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(4 * embed_size, embed_size),
nn.Dropout(dropout)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.ln1(x)
x = x + self.attention(x, x, x)[0]
x = x + self.ff(self.ln2(x))
return x
트랜스포머의 인코더 모듈을 구현한다. ViT에서는 디코더 구조가 사용되지 않으므로, 디코더는 따로 구현할 필요가 없다.
코드를 살펴보면 다음의 순서대로 계산이 이루어지는 것을 알 수 있다.
-
x = self.ln1(x)
입력 x에 먼저 layer normalization을 적용해준다.
-
x = x + self.attention(x, x, x)[0]
query, key, value에 모두 같은 값 x를 넣어 self attention을 계산한다. 결과에는 residual connection으로 입력값 x가 다시 더해진다.
-
x = x + self.ff(self.ln2(x))
위의 결과값에 다시 한번 layer normalization을 취해준 후, 작은 feed forward network에 집어넣는다.
위 코드를 자세히 보면 layer normalization을 적용하는 순서가 원래의 Attention is All You Need 논문에 나오는 것과는 다르다는 것을 알 수 있다. 이를 (직관적이게도) Pre-LN Transformer라고 부른다. 원본 논문의, layer normalization을 나중에 해주는 Post-LN Transformer가 학습이 불안정하고, 이 때문에 learning rate warmup 등의 복잡한 테크닉들을 요구했던 것에 비해 위 구현에서 사용된 Pre-LN Transformer는 훨씬 안정적인 훈련 과정을 보여준다. 자세한 설명은 잘 설명한 블로그 글이 있으니 참고하자.
여기에서 어텐션 메커니즘의 핵심인 multihead attention 모듈은 torch에서 제공하는 것을 그대로 사용하였으나, 기본적으로 query와 key, value에 해당하는 가중치 행렬을 곱한 후 attention 공식
$$\text{Attention} (Q, K, V) = \text{softmax}_{\text{dim=1}}\left(\frac{QK^T}{\sqrt{d_K}}\right)V$$
을 적용하는 것 뿐이니 어렵지 않다. 인터넷의 많은 글들에서 트랜스포머를 직접 구현하는 방법을 알려주고 있으니, 여기에서는 Vision Transformer의 Vision 부분에 보다 집중하기 위해 생략하도록 하자.
어텐션 메커니즘을 담고 있는 transformer encoder 블록을 구현하였으니, 이를 사용해서 Vision Transformer 모듈 자체를 구현할 차례이다.
class VisionTransformer(nn.Module):
def __init__(self, in_channels=3, num_encoders=6, embed_size=768, img_size=(324, 324), patch_size=16, num_classes=10, num_heads=4):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
num_tokens = (img_size[0]*img_size[1])//(patch_size**2)
self.class_token = nn.Parameter(torch.randn((embed_size,)), requires_grad=True)
self.patch_embedding = nn.Linear(in_channels*patch_size**2,embed_size)
self.pos_embedding = nn.Parameter(torch.randn((num_tokens+1, embed_size)), requires_grad=True)
self.encoders = nn.ModuleList([
Encoder(embed_size=embed_size, num_heads=num_heads) for _ in range(num_encoders)
])
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_size),
nn.Linear(embed_size, num_classes)
)
def forward(self, x):
batch_size, channel_size = x.shape[:2]
patches = x.unfold(2, self.patch_size, self.patch_size).unfold(3, self.patch_size, self.patch_size)
patches = patches.contiguous().view(x.size(0), -1, channel_size*self.patch_size*self.patch_size)
x = self.patch_embedding(patches)
class_token = self.class_token.unsqueeze(0).repeat(batch_size, 1, 1)
x = torch.cat([class_token, x], dim=1)
x = x + self.pos_embedding.unsqueeze(0)
for encoder in self.encoders:
x = encoder(x)
x = x[:,0, :].squeeze()
x = self.mlp_head(x)
return x
논문에도 나와있듯이, Vision Transformer는 이미지를 가로세로로 잘라 패치들의 모음으로 만들어준 후 Encoder에 넣어준다. 코드를 자세히 뜯어보자.
입력을 패치들로 분할하기
먼저, 모델에 입력되는 텐서의 모양을 알아야 한다. 이미지 데이터를 담고 있는 배치가 입력으로 들어오는데, 그 모양은 $(B, C, H, W)$, 즉 (배치 크기, 채널 수, 높이, 너비) 형태이다.
batch_size, channel_size = x.shape[:2]
patches = x.unfold(2, self.patch_size, self.patch_size).unfold(3, self.patch_size, self.patch_size)
patches = patches.contiguous().view(x.size(0), -1, channel_size*self.patch_size*self.patch_size)
첫 줄에서는 입력 데이터의 shape에서 batch size와 channel size, 즉 $B$와 $C$를 읽어온다. 채널 사이즈는 기본적으로 RGB 이미지라면 3, 흑백이라면 1일 것이다. 이를 이용해 이미지를 패치 단위로 분할하게 된다. 이때 사용되는 torch.unfold() 함수는 dimension, size, step을 입력으로 받아 텐서의 dimension 차원에서 size개의 원소들을, step을 스트라이드로 하여 가져오는 함수이다. 즉,
x.unfold(2, self.patch_size, self.patch_size)
를 하면 x의 2번째, 즉 높이에 해당하는 차원에서 self.patch_size개씩의 원소를 self.patch_size만큼을 간격으로 하여 추출한다. 예를 들어 원래 텐서가 (10, 3, 28, 28)의 차원을 가졌다면, self.patch_size = 7에 대해 위 작업을 실행하고 나서는 (10, 3, 4, 28, 7)의 차원을 가지게 된다. 원래의 2번째 차원(높이)은 이제는 높이 축에서 패치를 선택하는 차원이 되는 것이다.
.unfold(3, self.patch_size, self.patch_size)
여기에 3번째 차원(너비)에 대해서도 같은 작업을 시행해주면 (10, 3, 4, 4, 7, 7)과 같은 차원을 갖는 텐서가 된다. 3번째 차원도 너비 축으로 패치를 선택하는 차원이 된 것이다.
patches = patches.contiguous().view(x.size(0), -1, channel_size*self.patch_size*self.patch_size)
.contiguous()는 메모리상에서 텐서가 연속되게 저장되도록 바꾸어, 향후 연산이 효율적으로 이루어지게 하는 역할을 한다. 이후 .view()를 적용해 텐서를 원하는 모양으로 바꾼다. 앞선 (10, 3, 28, 28) 모양 배치를 예시로 들면, 이 줄까지 실행되고 나면 patches는 이제 (10, 4*4, 3*7*7) 모양이 된다. 4*4=16이 패치의 수이고, 3*7*7이 각 패치에 속하는 픽셀의 수이다.
논문에 나온 것처럼, 가로세로로 이미지를 잘라 패치들로 만들고, 각 패치에 속한 픽셀들을 linear하게 펴주는 작업이 완료되었다!
입력을 임베딩 벡터로 변환하기
x = self.patch_embedding(patches)
class_token = self.class_token.unsqueeze(0).repeat(batch_size, 1, 1)
x = torch.cat([class_token, x], dim=1)
x = x + self.pos_embedding.unsqueeze(0)
아직까지 patches는 입력 텐서를 모양만 바꾼 것에 불과하다. 입력 텐서를 분할해 만든 각각의 패치들을 임베딩 공간으로 매핑시켜주어야 한다. 이 코드에서는 self.patch_embedding이 그러한 역할을 수행한다.
코드의 __init__() 함수를 보면, self.patch_embedding은 다음과 같이 linear layer, 즉 행렬 하나로 정의된다.
self.patch_embedding = nn.Linear(in_channels*patch_size**2,embed_size)
즉, 각각의 패치를 미리 정해져 있는 embedding_size 차원으로 매핑시켜주는 역할을 하는 것이 바로 self.patch_embedding이다.
이렇게 만들어진 임베딩 벡터들에 class token을 맨 앞에 붙여 준다. 이는 자연어 처리에 사용되는 트랜스포머에서 맨 앞에 CLS 토큰을 추가해주었던 것과 마찬가지이다. Vision Transformer에서도 class token에서 나오는 출력을 입력 이미지들의 임베딩으로 사용하고, 이를 이용해서 분류 작업을 수행할 것이다.
마지막으로, Positional Embedding(위치 임베딩)을 더해주면 트랜스포머의 Encoder 모듈에 들어갈 준비가 끝난다. Positional embedding이 없다면 위치 정보에 독립적인 어텐션 메커니즘의 특성상, 각 패치가 이미지에서 위치상 어느 부분에 속했는지에 관한 정보가 완전히 손실되고 말 것이다. Positional emedding은 아래와 같이 학습가능한 파라미터들로 설정해준다.
self.pos_embedding = nn.Parameter(torch.randn((num_tokens+1, embed_size)), requires_grad=True)
Encoder 모듈에 전달하기
for encoder in self.encoders:
x = encoder(x)
x = x[:,0, :].squeeze()
x = self.mlp_head(x)
이제 앞서 정의한 트랜스포머 Encoder에 입력 임베딩들을 입력으로 넣어줄 차례다. Encoder 모듈들의 리스트인 self.encoders를 순회하면서 각 인코더에 입력을 통과시켜준다.
x = x[:,0, :].squeeze()
마지막 인코더의 출력까지 모두 얻은 다음에는, 0번째 토큰, 즉 class token의 출력만 추출한다. 앞서 말했듯이 이를 이미지 전체의 임베딩으로 사용하기 때문이다.
마지막으로, x를 분류 헤드인 MLP에 입력으로 넣어 최종 결과를 얻는다.
torchinfo로 구현 확인하기
from torchinfo import summary
device = "cuda" if torch.cuda.is_available() else "cpu"
model = VisionTransformer(in_channels=1, img_size=(28, 28), patch_size=7, embed_size=64, num_heads=4, num_encoders=3).to(device)
summary(model, [2, 1, 28, 28])
모델 훈련을 위한 코드를 작성하기 전에, torchinfo를 이용해서 모델이 오류 없이 출력을 잘 만들어내는지 확인해보자.
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VisionTransformer [2, 10] 1,152
├─Linear: 1-1 [2, 16, 64] 3,200
├─ModuleList: 1-2 -- --
│ └─Encoder: 2-1 [2, 17, 64] --
│ │ └─LayerNorm: 3-1 [2, 17, 64] 128
│ │ └─MultiheadAttention: 3-2 [2, 17, 64] 16,640
│ │ └─LayerNorm: 3-3 [2, 17, 64] 128
│ │ └─Sequential: 3-4 [2, 17, 64] 33,088
│ └─Encoder: 2-2 [2, 17, 64] --
│ │ └─LayerNorm: 3-5 [2, 17, 64] 128
│ │ └─MultiheadAttention: 3-6 [2, 17, 64] 16,640
│ │ └─LayerNorm: 3-7 [2, 17, 64] 128
│ │ └─Sequential: 3-8 [2, 17, 64] 33,088
│ └─Encoder: 2-3 [2, 17, 64] --
│ │ └─LayerNorm: 3-9 [2, 17, 64] 128
│ │ └─MultiheadAttention: 3-10 [2, 17, 64] 16,640
│ │ └─LayerNorm: 3-11 [2, 17, 64] 128
│ │ └─Sequential: 3-12 [2, 17, 64] 33,088
├─Sequential: 1-3 [2, 10] --
│ └─LayerNorm: 2-4 [2, 64] 128
│ └─Linear: 2-5 [2, 10] 650
==========================================================================================
Total params: 155,082
Trainable params: 155,082
Non-trainable params: 0
Total mult-adds (M): 0.21
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.38
Params size (MB): 0.42
Estimated Total Size (MB): 0.81
==========================================================================================
Summary가 잘 출력되는 것으로 보아, 모델이 잘 구현된 것을 알 수 있다!
이제 모델을 다 구현하였으니, MNIST 데이터셋에서 훈련을 시켜보자.
데이터셋 준비하기
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307], std=[0.3081])
])
train_data = datasets.MNIST(root = './data/02/',
train=True,
download=True,
transform=data_transforms)
test_data = datasets.MNIST(root = './data/02/',
train=False,
download=True,
transform=data_transforms)
datasets 모듈을 사용해 MNIST 데이터셋을 가져온다. 원활한 훈련을 위해 입력 이미지를 평균 0, 표준편차 1로 normalize시켜준다.
훈련 준비
from tqdm import tqdm
train_dl = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_data, batch_size=1024, shuffle=False)
optimizer = torch.optim.Adam(lr=5e-4, params=model.parameters())
criterion = nn.CrossEntropyLoss()
데이터셋을 공급해주는 훈련용/테스트용 DataLoader를 정의하고, optimizer와 손실 함수를 정의한다. 위 코드에서 볼 수 있듯이 무난하게 Adam Optimizer를 사용하고 분류 작업에서 일반적으로 사용되는 Cross entropy loss를 사용한다.
LRFinder를 이용해 최적의 학습률을 찾아주자.
lr_finder = LRFinder(model, optimizer, criterion, device="cuda")
lr_finder.range_test(train_dl, end_lr=100, num_iter=100)
lr_finder.plot() # to inspect the loss-learning rate graph
lr_finder.reset() # to reset the model and optimizer to their initial state
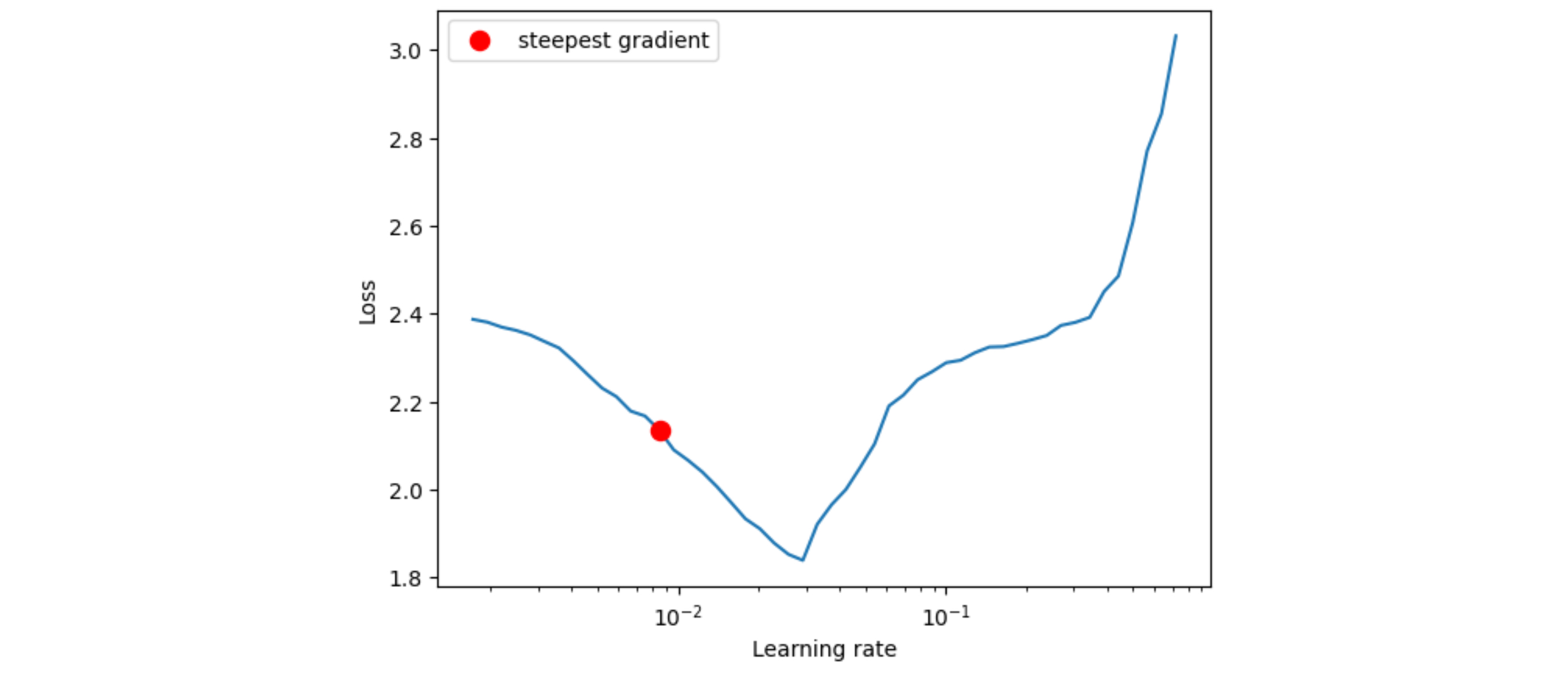
LRFinder가 찾아준 learning rate 1e-2를 이용해 학습을 진행한다.
메인 훈련 루프
# optimizer = torch.optim.Adam(params=model.parameters(), lr=8.52E-03)
epochs = 10
for epoch in range(epochs):
losses = []
print(f"Epoch {epoch+1} / {epochs}", end=" ")
for image, label in tqdm(train_dl):
image, label = image.to(device), label.to(device)
pred = model(image)
loss = criterion(pred, label)
loss.backward()
losses.append(loss.item())
optimizer.step()
optimizer.zero_grad()
print(f"loss: {sum(losses) / len(losses)}", end=" ")
with torch.no_grad():
cnt, correct_cnt = 0, 0
for image, label in test_dl:
image, label = image.to(device), label.to(device)
pred = model(image).argmax(dim=1)
cnt += label.shape[0]
correct_cnt += (pred==label).sum().item()
print("accuracy: ", correct_cnt / cnt)
torch.save(model.state_dict(), './model.pt')
10 epoch동안 학습을 진행한다.
Epoch 1 / 10 100%|██████████| 938/938 [00:28<00:00, 33.37it/s]
loss: 0.4348547394071688 accuracy: 0.946
Epoch 2 / 10 100%|██████████| 938/938 [00:21<00:00, 43.99it/s]
loss: 0.16588843942109519 accuracy: 0.9559
Epoch 3 / 10 100%|██████████| 938/938 [00:21<00:00, 43.94it/s]
loss: 0.12110982257733817 accuracy: 0.9645
Epoch 4 / 10 100%|██████████| 938/938 [00:21<00:00, 44.38it/s]
loss: 0.10210576851361755 accuracy: 0.9732
Epoch 5 / 10 100%|██████████| 938/938 [00:21<00:00, 43.90it/s]
loss: 0.08337713227615252 accuracy: 0.9719
Epoch 6 / 10 100%|██████████| 938/938 [00:21<00:00, 43.61it/s]
loss: 0.07553793193483507 accuracy: 0.9747
Epoch 7 / 10 100%|██████████| 938/938 [00:21<00:00, 43.96it/s]
loss: 0.06684430059530079 accuracy: 0.9745
Epoch 8 / 10 100%|██████████| 938/938 [00:21<00:00, 44.44it/s]
loss: 0.06126855420413366 accuracy: 0.9792
Epoch 9 / 10 100%|██████████| 938/938 [00:21<00:00, 42.85it/s]
loss: 0.0536487325038046 accuracy: 0.976
Epoch 10 / 10 100%|██████████| 938/938 [00:20<00:00, 44.79it/s]
loss: 0.05059714574190075 accuracy: 0.979
하이퍼파라미터 튜닝을 별도로 진행하지 않았음에도 불구하고 0.979의 높은 정확도를 얻을 수 있었다.
훈련 결과 시각화하기
import matplotlib.pyplot as plt
with torch.no_grad():
for image, _ in test_dl:
image = image[:64]
image = image.to(device)
pred = model(image).argmax(dim=1).cpu().detach().numpy()
image = image.cpu().detach().numpy()
break
fig, axes = plt.subplots(8, 8, figsize=(15, 15))
for i in range(64):
axes[i//8][i%8].set_title(pred[i])
axes[i//8][i%8].imshow(image[i][0])

64개의 이미지 모두 정확하게 분류된 것을 확인할 수 있다!