필자가 Princeton University가 Coursera에서 제공하는 Computer Architecture (Instructor: David Wentzlaff)를 듣고 일부를 요약해 정리한 글입니다.

이 글에서는 병렬 프로그래밍을 위한 아키텍처인 Vector, SIMD(Single Instruction, Multiple Data), 그리고 GPU를 소개한다.
Vector
먼저 벡터 프로세서의 정의를 알아보자.
In computing, a vector processor or array processor is a central processing unit (CPU) that implements an instruction set where its instructions are designed to operate efficiently and effectively on large one-dimensional arrays of data called vectors. (Wikipedia)
즉, 벡터 프로세서는 vector라고 불리는 1차원 배열에 대한 일괄적인 연산을 지원하는 아키텍처를 갖추고 있어야 한다. 이러한 벡터 아키텍처는 어떻게 구현되고, 어떻게 사용할 수 있는지 간략하게 알아본다.
Vector Programming Model
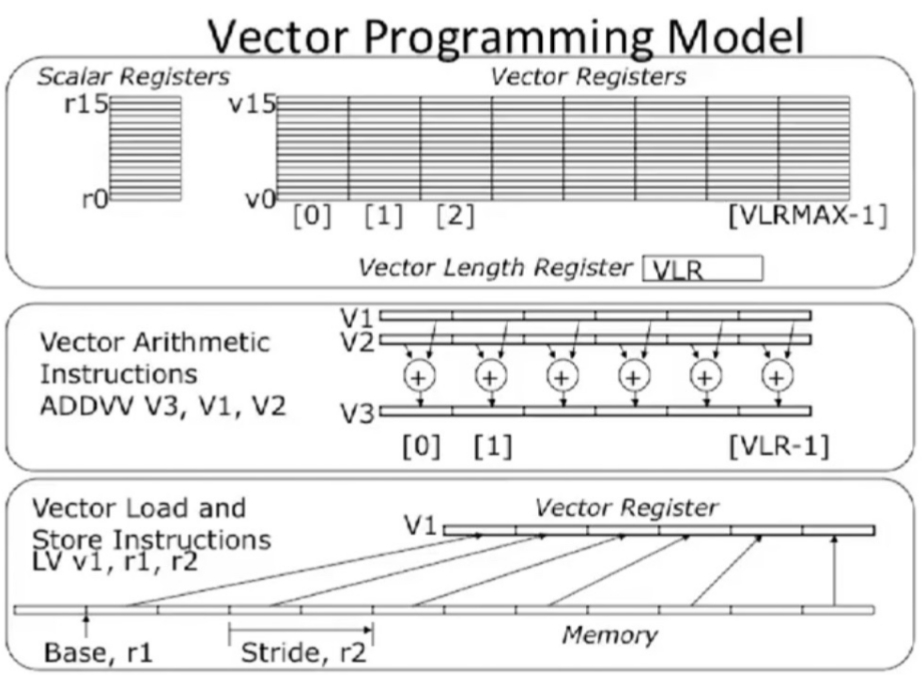
소프트웨어의 입장에서 바라본 Vector Programming Model을 먼저 알아보자. 먼저 벡터 프로세서에는 벡터, 즉 1차원 배열을 저장하기 위한 vector register가 있다. 또한 VLR(Vector Length Register)이라고 불리는 스칼라 레지스터가 있어 벡터의 최대 길이를 정할 수 있게 되어 있다.
Vector 프로그래밍을 지원하는 대표적인 아키텍처로는 VMIPS가 있는데, 이름에서도 알 수 있듯 MIPS에서 파생된 아키텍처이다. VMIPS에서는 MIPS의 스칼라 연산 instruction명에 V와 S를 붙여 벡터 연산임을 명시한다. 예를 들어,
ADDVV는 두 벡터 사이의 덧셈을 의미한다.ADDVS는 벡터 하나와 스칼라 하나 사이의 덧셈을 의미한다. 즉, 동일한 스칼라 변수가 벡터의 각 원소에 똑같이 더해진다.
이렇게 벡터 연산을 하기 위해서는 먼저 벡터 레지스터에 값들이 저장되어 있어야 할 것이다. VMIPS에서는 메인 메모리로부터 벡터 레지스터로 값을 불러오고 저장하기 위해 vector load/store 연산들을 지원한다. 예를 들어,
LV v1, r1, r2는 r1에서 시작해 r2의 stride로 메모리에 접근하여 r1, r1 + r2, r1 + 2 * r2, $\cdots$의 주소에 있는 값들을 차례대로 벡터 레지스터 v1에 불러오도록 한다.
LV v1, r1이라고만 하면 stride r2가 기본값인 1로 설정된다.
Example: Element-wise Multiplication
다음의 C 코드를 스칼라와 벡터를 사용해 각각 컴파일한다고 해보자.
for(i = 0; i < 64; i++){
C[i] = A[i] * B[i];
}
# Scalar Assembly Code
LI R4, 64
loop:
L.D F0, 0(R1)
L.D F2, 0(R2)
MUL.D F4, F2, F0
S.D F4, 0(R3)
DADDIU R1, 8
DADDIU R2, 8
DADDIU R3, 8
DADDIU R4, 1
DADDIU R1, 8
BNEZ R4, loop
스칼라 프로세서에서는 실제로 i의 값을 증가시켜 가면서 &A[i]와 &B[i]에 접근해 이들 값을 레지스터로 불러오고, 이를 곱한 후 &C[i]의 주소로 저장하는 과정을 수행해야 한다. 반면 벡터를 사용할 때를 보자.
# Vector Assembly Code
L1 VLR, 64
LV V1, R1
LV V2, R2
MULVV.D V3, V1, V2
SV V3, R3
벡터의 경우 vector length register에 item의 개수인 64를 대입한 후, A[i]과 B[i] (i=0, 1, ... 63)를 각각 LV를 사용해 벡터 레지스터에 로딩해온 후 MULVV.D를 사용해 한번에 곱셈을 수행할 수 있다.
Vector Arithmetic Execution
벡터 프로세서들은 매우 깊은 pipeline을 사용해 vector register에 저장된 element들을 하나씩 연산을 한다. pipeline이 깊다는 것은 연산 로직을 잘게 쪼개 놓았다는 것을 의미하므로 clock을 높게 설정할 수 있고, 연산을 빠르게 수행하는 것이 가능하다. 이때 벡터의 각 원소들은 서로 독립적이므로 data hazard이 발생하지 않아 bypassing 등은 불필요하다.
Interleaved Vector Memory System
한편, vector가 탑재된 system의 경우 메모리 시스템에 변경이 필요하다. Vector load 연산을 할 경우 메모리 read의 횟수가 너무 많기 때문에, memory load 과정을 interleaving할 수 있어야 하기 때문이다.
이를 위해 많은 벡터 시스템은 메인 메모리에 banking을 도입한다. 예시로 Cray-1의 메인 메모리는 16개의 memory bank로 이루어져 있어, 각각이 전체 주소 공간의 $\frac{1}{16}$에 해당하는 데이터를 저장하는 것이다. Cray-1에서 각각의 bank는 busy time (bank가 다음 request를 받을 준비가 되기까지 걸리는 시간)이 4 사이클, latency가 16 사이클으로 설계되어 있다. 즉 (벡터의 최대 길이인) 64개의 원소를 로딩한다면, 각 bank에 타겟 주소가 고르게 분포한다는 가정 하에 $4 \times 3 + 16 = 28$ 사이클만에 64개의 원소를 벡터 레지스터에 로드할 수 있다.
Vector Processing Optimization
Example: Pipeline Diagram
for(i = 0; i < 4; i++){
C[i] = A[i] * B[i];
}
라는 코드가 주어져 있을 때, 컴파일된 어셈블리가 다음과 같다고 가정하고 벡터 프로세서가 이를 처리하는 pipeline diagram을 그려보자.
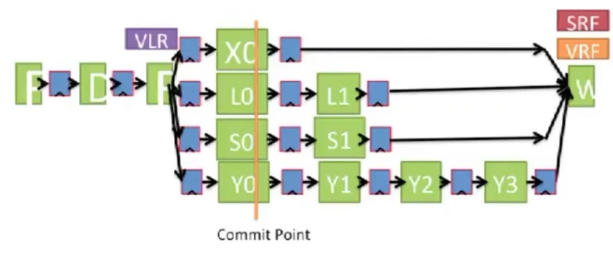
파이프라인은 위와 같은 구조라고 가정한다. 여기서 F, D, R, W은 각각 fetch, decode, register access, write-back이고 X, L, S, Y는 각각 덧셈, memory load/store, 곱셈이라고 가정한다.
LI VLR, 4
LV V1, R1
LV V2, R2
MULVV.D V3, V1, V2
SV V3, R3
| LV V2.. | F | D | R | L0 | L1 | W | | | | | | | | | | | | | | | | | | | |
| | | | | R | L0 | L1 | W | | | | | | | | | | | | | | | | | | |
| | | | | | R | L0 | L1 | W | | | | | | | | | | | | | | | | | |
| | | | | | | R | L0 | L1 | W | | | | | | | | | | | | | | | | |
| MULVV.D | | F | D | D | D | D | D | D | D | R | Y0 | Y1 | Y2 | Y3 | W | | | | | | | | | | |
| | | | | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | | | | | | |
| | | | | | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | | | | | |
| | | | | | | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | | | | |
| SV | | | F | F | F | F | F | F | F | D | D | D | D | D | D | D | D | D | R | S0 | S1 | W | | | |
| | | | | | | | | | | | | | | | | | | | | R | S0 | S1 | W | | |
| | | | | | | | | | | | | | | | | | | | | | R | S0 | S1 | W | |
| | | | | | | | | | | | | | | | | | | | | | | R | S0 | S1 | W |
벡터 instruction의 실행에서 chime이라는 개념을 정의할 수 있다. 이는 instruction을 실행하기 시작하는 데 걸리는 overhead를 모두 제외하고, 해당 instruction으로 vector sequence를 처리하는 데 걸리는 시간을 의미한다. 위의 경우, vector length가 4일 때 chime이 4라고 말할 수 있다.
diagram을 보면, LV에서 4개의 load가 모두 완료될 때까지 다음 단계가 진행되지 않는 비효율이 발생하는 것을 알 수 있다.
특히 위의 pipeline diagram에서는 각 cycle에 하나의 functional unit만이 실행되었다. 이를 개선하여, superscalar processor처럼 여러 FU가 동시에 실행될 수 있도록 할 수 있다. 이렇게 vector instruction parallelism을 최대한 exploit할 수 있도록 하드웨어를 개선해보자.
Vector Chaining
벡터 프로세서에서도 기존 스칼라 프로세서의 bypassing과 유사한 테크닉을 사용할 수 있다. 이를 Vector Chaining이라 한다.
LV V1
MULVV V3, V1, V2
ADDVV V5, V3, V4
예를 들어 위의 코드에서는 LV V1의 결과로 나온 V1 레지스터의 값이 곧바로 MULVV의 입력으로 들어가게 되고, MULVV의 결과로 나온 V3는 다시 ADDVV의 입력으로 들어가게 된다.
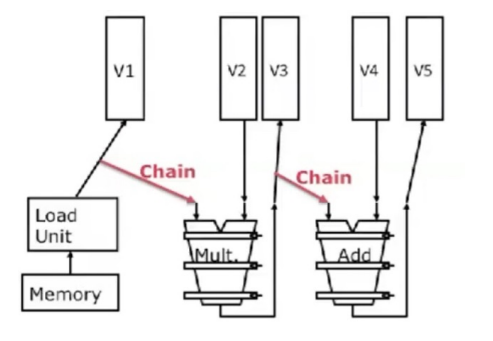
이때 chaining(혹은 기존 용어로 bypassing)은 register file을 거쳐서 일어난다. 즉, 스칼라 프로세서에서 흔히 보던 것처럼 execution stage가 끝나 값이 생성되자마자 다음 사이클에 이를 사용해 다른 instruction이 execution을 할 수 있게 되는 것은 아니고, register에 write를 하고 다시 read를 하는 과정이 필요하다. 따라서 두 사이클(앞선 instruction의 register write, 이에 의존하는 instruction의 register read)의 낭비가 발생하게 된다.
Vector chaining이 적용된 경우를 가정하고 pipeline diagram을 다시 그려보자.
| LV V2.. | F | D | R | L0 | L1 | W | | | | | | | | | | | | | |
| | | | | R | L0 | L1 | W | | | | | | | | | | | | |
| | | | | | R | L0 | L1 | W | | | | | | | | | | | |
| | | | | | | R | L0 | L1 | W | | | | | | | | | | |
| MULVV.D | | F | D | D | D | D | R | Y0 | Y1 | Y2 | Y3 | W | | | | | | | |
| | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | | | |
| | | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | | |
| | | | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | |
| SV | | | F | F | F | F | D | D | D | D | D | D | R | S0 | S1 | W | | | |
| | | | | | | | | | | | | | | R | S0 | S1 | W | | |
| | | | | | | | | | | | | | | | R | S0 | S1 | W | |
| | | | | | | | | | | | | | | | | R | S0 | S1 | W |
이때 MULVV.D의 첫 사이클을 보면 LV V2, R2의 첫 번째 item이 레지스터 파일에 write될 까지 기다린 후 이를 읽어오기 때문에 앞서 설명한 것과 같이 2사이클이 낭비되는 것을 알 수 있다. 레지스터 파일을 거치지 않고 스칼라 프로세서에서 하는 것처럼 bypassing network를 사용하면 이 낭비를 줄일 수 있으나, 이 경우 레지스터 파일을 multiported로 바꾸지 않는 한 register read에서 structural hazard가 발생하게 된다.
만약 레지스터 파일이 multiported라 vector chaining이 레지스터를 거치지 않아도 되는 경우, pipeline diagram은 다음과 같을 것이다.
| LV V2.. | F | D | R | L0 | L1 | W | | | | | | | | | |
| | | | | R | L0 | L1 | W | | | | | | | | |
| | | | | | R | L0 | L1 | W | | | | | | | |
| | | | | | | R | L0 | L1 | W | | | | | | |
| MULVV.D | | F | D | D | R | Y0 | Y1 | Y2 | Y3 | W | | | | | |
| | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | | |
| | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | |
| | | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | |
| SV | | | F | F | D | D | D | D | R | S0 | S1 | W | | | |
| | | | | | | | | | | R | S0 | S1 | W | | |
| | | | | | | | | | | | R | S0 | S1 | W | |
| | | | | | | | | | | | | R | S0 | S1 | W |
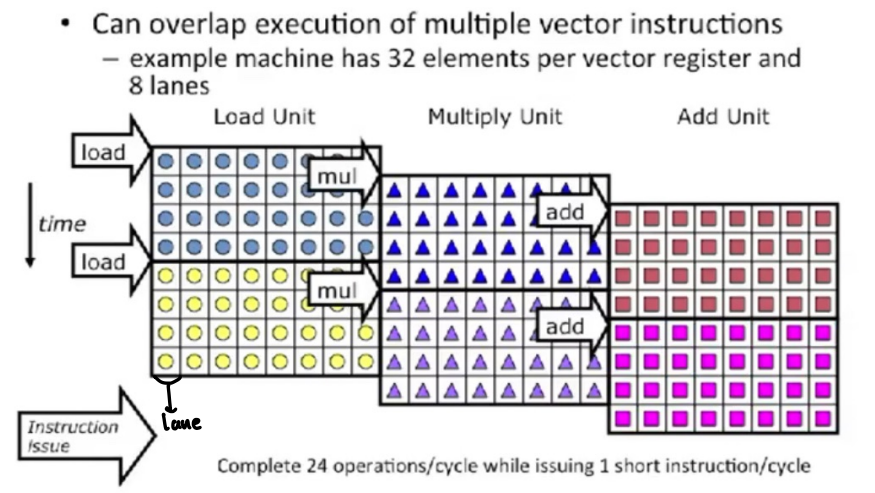
Vector Instruction Execution with Multiple Lanes
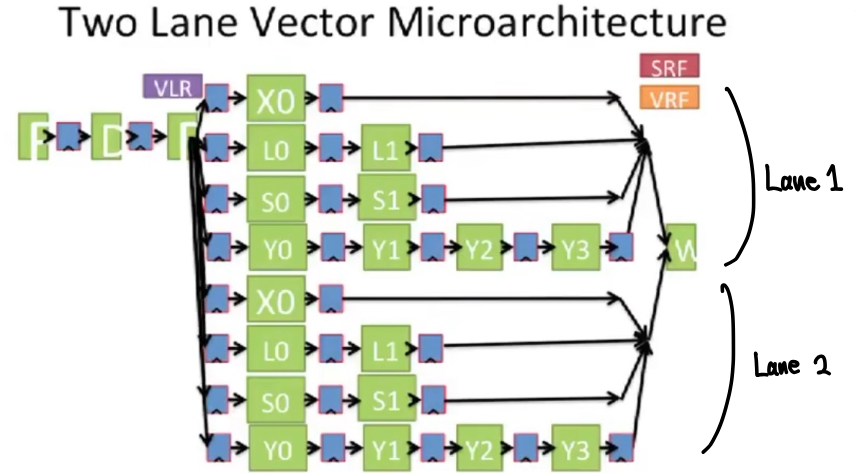
Chime을 감소시키기 위해서는 execution step의 병렬화가 필요하다. 이를 위해서는 위 그림과 같이 동일한 functional unit 들이 두 개 이상씩 있어야 한다.
위의 그림과 같은 2-way vector stripping이 적용된 경우, pipeline diagram은 다음과 같이 바뀌게 된다.
| LV V2... | F | D | D | R | L0 | L1 | W | | | | | | | |
| | | | | | R | L0 | L1 | W | | | | | | |
| | | | | R | L0 | L1 | W | | | | | | | |
| | | | | | R | L0 | L1 | W | | | | | | |
| MULVV.D | | | F | D | D | R | Y0 | Y1 | Y2 | Y3 | W | | | |
| | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | |
| | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | | |
| | | | | | | | R | Y0 | Y1 | Y2 | Y3 | W | | |
| SV | | | | F | F | D | D | D | D | R | S0 | S1 | W | |
| | | | | | | | | | | | R | S0 | S1 | W |
| | | | | | | | | | | R | S0 | S1 | W | |
| | | | | | | | | | | | R | S0 | S1 | W |
다이어그램을 보면, 각각의 명령어(LV, MULVV.D, SV)를 처리할 때 두 개씩의 operation이 짝지어서 동시에 일어난다. 예를 들어서, 다이어그램의 첫 두 줄은 A[0]와 A[2]가 로딩되는 것으로, 그 다음 두 줄은 A[1]과 A[3]가 로딩되는 것으로 생각할 수 있다. 이를 통해 chime은(VLR=4일 때) 4에서 2로 감소한다. 이것은 동일 functional unit이 두 개씩 있기에 가능한 것이다.
Vector Stripmining
지금까지는 벡터 레지스터에 들어가는 원소의 수가 많지 않은 경우만을 다루었으나, 벡터 레지스터에 들어갈 수 있는 원소의 개수는 유한하다. 따라서 이를 넘는 길이의 array에 대해서는 vector instruction을 여러 번 쪼개어 실행해주어야 한다. 이를 vector stripmining이라고 한다.
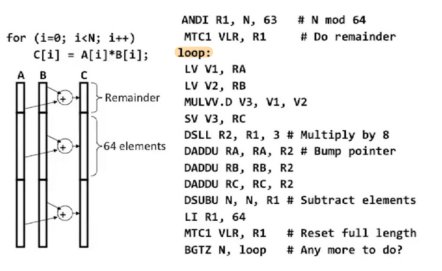
그림의 코드의 경우에는 최대 벡터 길이가 64인 아키텍처로, $N\mod 64$개의 원소에 대해 먼저 계산을 마친 후 64개씩 반복하여 계산을 하는 것을 알 수 있다. Vector stripmining을 하는 경우 이처럼 벡터 연산 자체를 제외하더라도 추가적인 처리를 하는 코드의 비중이 많아지므로, $N$이 상대적으로 작다면 이러한 처리의 overhead의 비중이 커져 성능이 기대에 미치지 못할 수 있다.
Vector ISA의 장점
Vector 프로세서는 일반적인 스칼라 프로세서에 비해 다음과 같은 장점을 가진다.
- Compact: 한 instruction이
N개의 operation을 인코딩하고 있으므로 명령어 코드가 더 간결하다.
- Expressive: Vector ISA로 instruction을 표현할 시,
N개의 instruction들이
- independent하고
- 동일한 functional unit을 사용하며
- 사용하는 register가 겹치지 않고 (즉 dependence, data hazard가 없고)
- 이전 instruction과 같은 패턴의 access를 하며
- 메모리의 연속적인 블록들을 이용하며
- strided load/access의 패턴으로 메모리에 접근함을 하드웨어에 암시적으로 알려줄 수 있다.
- Scalable: lane을 더해 확장된 파이프라인에서도 동일한 코드를 실행할 수 있다.
Code Vectorization
코드를 컴파일 할 때, sequential한 코드를 재배열하여 벡터를 활용한 코드를 만드는 것을 code vectorization(코드 벡터화)이라고 한다. 이는 반복문의 각 iteration간 의존성에 대한 깊은 분석이 필요하다. 이 단락에서는 반복문에서 흔히 발생하는 여러 패턴들을 vectorize하는 여러 예시를 소개한다.
Conditional Execution
for(i = 0; i < N; i++){
if(A[i] > 0) A[i] = B[i];
}
위 코드의 경우 배열의 모든 원소에 대해서 동일한 연산이 적용되지 않고 있다. A[i]가 양수인 경우에만 대입 연산을 실행하기 때문이다. 이러한 경우, predicated register의 벡터 버전이라고도 할 수 있는 vector mask(또는 vector flag)를 추가하여 코드를 벡터화할 수 있다. Vector mask는 각 원소당 1bit를 차지하도록 되어 있는 배열으로, 각각의 원소에 대해 연산을 적용할지 말지를 명시해주는 역할을 한다.
Conditional execution을 구현하는 방법에는 크게 두 가지가 있을 것이다.
- 단순한 방법으로, 계산 자체는 모두 수행한 후 mask bit를 레지스터 쓰기에 대한 enabler로 사용하는 방법이 있다.
- 더욱 효율적인 방법으로, mask vector 전체를 한번 읽은 후, 실행 자체를 mask가 0이 아닌 원소들에 대해서만 할 수 있다.
- 이 경우 구현이 어려워 널리 사용되지는 않는다.
Vector Reductions
Vector reduction이란 벡터를 입력으로 받아 스칼라를 반환하는 연산을 의미한다. 간단한 예시로 벡터 전체의 합을 구하는 것이 있을 것이다.
sum = 0;
for(i = 0; i < N; i++)
sum += A[i];
위 코드의 경우 표면적으로는 sum이라는 변수에 inter-loop dependence가 있다. 그러나 코드를 다음과 같이 변형하면 dependency를 없애고 벡터 연산들을 효율적으로 활용할 수 있다.
sum[0:VL-1]
for(i = 0; i < N; i+= VL)
sum[0:VL-1] += A[i:i+VL-1] // accumulate A[VL * k + i]'s to sum[i]
do{
VL = VL / 2;
sum[0:VL-1] += sum[VL:2*VL-1]
} while (VL > 1)
위처럼 이진트리와 같이 벡터간의 덧셈을 반복적으로 실행하면 $\lceil\lg N\rceil$번 만에 합을 구할 수 있다.
Vector Scatter/Gather
for(i = 0; i < N; i++)
A[i] = B[i] + C[D[i]];
위 코드의 경우 loop에 indirect access가 존재한다. 접근해야 할 메모리 주소가 연속적이거나 strided pattern으로 주어지는 것이 아니라, 다른 벡터 레지스터에 저장되어 있는 것이다.
이러한 경우를 위해 vector scatter*와 vector gather**라는 instruction이 있다. Gather는 벡터에 저장되어 있는 주소로 메모리에 접근해 load하는 것을, scatter는 벡터에 저장되어 있는 주소로 메모리에 접근해 store하는 것을 의미한다.
위의 코드를 벡터 프로세서로 컴파일하면 vector scatter/gather를 활용해 아래와 같은 어셈블리 코드를 얻을 수 있다.
LV vD, rD
LVI vC, rC, vD
LV vB, rB
ADDV.D vA, vB, vC
SV vA, rA
SIMD
Single Instruction, Multiple Data(SIMD) 또는 Multimedia Extension은 벡터의 친척과도 같은 아키텍처로, 오늘날의 데스크탑 컴퓨터가 벡터 연산을 처리하는 방식이다. 일반적인 instruction이 한 instruction으로 하나의 데이터를 얻는 데 비해, SIMD instruction들은 여러 개의 데이터를 한번에 처리한다. 예를 들어, 64비트짜리 wide register에 32비트짜리 데이터 2개를 저장하는 식이다. 이러한 wide register 2개로 덧셈을 수행하면 32비트짜리 데이터 두 쌍에 대해 동시에 덧셈이 수행된다.
SIMD는 x86에서 MMX(MultiMedia eXtension)가 처음 도입된 이후, SSE, SSE2, SSE3를 거쳐 AVX(Advanced Vector eXtension)가 자리잡게 되면서 대중적으로 사용되게 되었다. 여기서 각각의 차이는 레지스터의 크기와 개수, instruction의 종류 등이다.
SIMD를 사용하기 위해서는 datapath 자체에 변형이 필요하다. 예를 들어 32비트 가산기를 8비트 정수 4쌍의 덧셈을 위해 사용한다면, carry chain을 끊어야 한다. 반면 bitwise OR, AND와 같은 연산의 경우에는 아무 변경 없이도 그냥 사용이 가능할 것이다.
SIMD vs Vectors
SIMD와 벡터의 차이점은 다음과 같다.
- SIMD는 벡터보다 ISA가 훨씬 제한적이다. 벡터의 길이를 조절할 수 없고, strided load/store가 없으며 unit stride load시에는 반드시 SIMD 레지스터의 boundary와 align이 필요하다.
- SIMD는 레지스터의 길이가 훨씬 짧다. 전형적인 vector 프로세서는 64개 원소를 저장할 수 있는 vector register를 가지고 있으나, AVX의 경우 멀티미디어 레지스터의 길이는 256비트에 불과하다.
- 따라서 SIMD의 경우 하나의 instruction으로 많은 작업을 할 수 없으니 superscalar dispatch가 필요하다.
한편, SIMD는 버전이 올라가며 점점 벡터와 유사하게 발전하고 있다. 최근 버전에서는 misaligned memory access나 double precision을 지원하며, New AVX(2008년)의 경우 1024비트까지 확장이 가능하여 더 많은 데이터를 한꺼번에 처리할 수 있도록 설계되어 있다.
GPUs
Graphic Processing Unit(GPU)는 원래는 general computing이 아닌 3D 그래픽 렌더링을 용도로 탄생한 프로세서이다. 이는 pixel shader 등의 몇 가지 목적으로만 사용되었고, 이 때문에 초기 GPU의 경우 프로그래밍할 수 있는 정도가 매우 제한적이었다. 이 때문에 일부 사용자들은 GPU의 퍼포먼스를 다른 작업에도 활용하기 위해 다른 작업들을 pixel shading과 같이 GPU가 지원하는 작업들로 매핑한 후, 그 출력값을 다시 원래의 도메인으로 매핑하는 식으로 GPU를 사용하였다.
이후 NVIDIA에서 CUDA(Compute Unified Device Architecture)가 출시되며, GPGPU(General-Purpose GPU)가 탄생하게 된다. 이를 통해 많은 프로그래머들이 GPU의 계산 성능과 메모리 대역폭을 general computing을 가속화시키는 데 사용할 수 있게 되었다.
GPGPU에서는 attached processor model이라는 것을 가정하는데, 이는 host CPU가 GPGPU에 data-parallel kernel을 issue하여 실행시키도록 하는 방식이다.
CUDA Programming Model
CUDA는 계산을 thread 단위로 수행한다. 이때 각각의 thread는 CUDA thread 또는 microthread라고 불리며, thread block이라는 단위로 묶인다. 각각의 thread가 서로 독립적인 scalar 연산을 병렬적으로 수행하는 식이다.
예시로 DAXPY를 수행하는 CUDA 코드를 살펴보자. DAXPY란 double-precision ax plux y의 약자로, 다음의 C 코드와 같은 일을 수행하는 작업이다.
void daxpy(int n, double a, double *x, double *y){
for(int i = 0; i < n; i++){
y[i] = a * x[i] + y[i];
}
}
이를 CUDA로 병렬화시킨 코드는 다음과 같다.
__host__ // Piece run on host processor
int nblocks = (n+255) / 256; // 256 CUDA threads/block
daxpy<<<nblocks,256>>>(n, 2.0, x, y)
__device__ // Piece run on GPGPU
void daxpy(int n, double a, double *x, double *y){
int i = blockIdx.x * blockDim.x + threadId.x;
if (i < n)
y[i] = a * x[i] + y[i];
}
CUDA를 사용하면 위와 같이 C에서 확장한 코드를 이용해, GPU에서 작업을 thread 단위로 병렬화하여 처리하는 것이 가능하다. CUDA의 이러한 특성을 Single Instruction, Multiple Thread(SIMT)라고 한다. Scalar instruction 하나만으로 (CUDA의 경우) 32개의 thread를 병렬로 실행할 수 있기 때문이다.
SIMT의 특징은 다음과 같이 설명할 수 있다.
- 모든 vector load/store instruction은 scatter/gather와 같다. 각각의 microthread가 각각 scalar load/store를 실시하기 때문이다.
- 각각의 microthread는 각자가 스스로가 active한지를 판별하여(위 코드의
i<n 부분에 해당) stripmining calculation을 수행해야 한다.
- 만약 microthread마다 control flow가 달라진다면 predication이 요구된다.