
Smith, James E., and Gurindar S. Sohi. "The microarchitecture of superscalar processors." Proceedings of the IEEE 83.12 (2002): 1609-1624.
Abstract
- Superscalar: instruction-level parallelism(ILP)를 이용해 매 사이클에 한 개 이상의 instruction을 실행가능
- 먼저 superscalar processor가 해결하는 하나의 일반적인 문제를 논의. "겉보기에는 sequential한 프로그램을 parallel하게 변환하는 것"
-
또 superscalar의 구현을 위해 사용되는 테크닉들을 다룸:
- instruction fetching & conditional branch processing
- register값에 대한 data dependence의 결정
- parallel execution을 위한 instruction issuing
- load/store를 이용한 data value의 통신
- interrupt를 정확히 처리하는, 올바른 순서로의 process state commit
-
논문 출간 당시의 최신 superscalar processor인 MIPS R10000, DEC 21164, AMD K5를 예시로 삼아 보여줌
1. Introduction
Superscalar processor의 등장은 RISC movement의 연장선상에 있는 것으로 여겨지지만, 그 구현은 점점 더 복잡해지고 있음.
-
DEC Alpha, RISC instruction set, Intel x86 등에 도입
일반적인 superscalar processor의 동작:
-
여러 instruction을 한꺼번에 fetch & decode
- IF 단계에서는 끊임없는 instruction 공급을 위해 branch prediction이 적용된
- data dependence 분석
- 각 functional unit에 instruction 배분
- operand의 값이 available해지면 병렬적으로 execution 시작
- 이를 dynamic instruction scheduling이라고 함
- 실행이 끝나면 결과는 re-sequence되어 original program order로 결과를 update
- 그래야 interrupt 발생시 상태를 올바르게 복원할 수 있기 때문
병렬적으로 실행되는 대상이 각각의 instruction이기 때문에 superscalar는 instruction-level parallelism(ILP)를 exploit한다고 말함
Historical Perspective
1960년대의 notable한 프로세서들:
- CDC 6600: parallel한 functional unit을 통해 ILP를 달성.
- 평균적인 CPI=1이었으나 instruction set, parallel processing unit, dynamic instruction scheduling 등에서 현대의 superscalar processor와 유사
- IBM 360/91
- heavily pipelined. Tomasulo's algorithm*을 통해 dynamic instruction issuing
- 평균 CPI는 1으로 superscalar는 아니었으나 큰 영향 끼침
이후에도 pipeline initiation rate는 1로 몇 년간 유지, 병목으로 작용함. 그동안 다른 parallelism 기법들이 탄생(vector, multiprocessing). 1970년대와 80년대를 거치면서 initiation rate이 1을 넘는 processor들도 설계되었으나 상용화되지는 않았음. 80년대 중후반에 이르러서야 single-instruction-per-cycle-bottleneck이 깨지고, superscalar processor가 시장에 나오기 시작하며 high-performance computing의 표준이 됨
The Insturction Processing Model
Processor design에 있어서는 binary compatibility를 고려해야 함.
-
이전 세대 processor의 프로그램을 실행할 수 있는 능력
sequential execution model: 예전 컴퓨터들의 실행 방식을 닮음.
-
precise state: interrupt 발생시 sequential execution model을 따라서, architectural state는 interrupt 전의 instruction까지는 완전히 실행되고 그 이후의 instruction들은 전혀 실행되지 않은 것처럼 바뀌어야 함
현대의 computer designer들도 binary compatibility와 sequential execution model을 유지해야 함.
- 그러나 실제 구현은 sequential execution에서 매우 많이 벗어남
- binary의 역할은 어떻게 할지보다 무엇을 할지 명세해놓은 것에 가까움
- 겉으로만 sequential execution처럼 보이게 할 뿐, 실제로는 불필요한 sequentiality를 전부 parallel하게 바꾸어 수행
성능 = 더 적은 시간에 수행을 마치는 것. 수행시간을 줄이기 위해서는 두 가지 방법
- instruction 각각의 latency를 줄이는 것
- insturction들을 더 parallel하게 실행 -> superscalar는 여기에 집중
- 그러나 latency를 더 늘리지 않는 것 또한 challenge (HW가 점점 복잡해지기 때문)
Parallel instruction processing은 다음을 필요로 함:
- dependence relation의 파악
- 여러 operation을 parallel하게 실행 가능한 HW 자원
- execution을 위해 필요한 피연산자 값이 준비되었는지 파악
- 값들을 operation간에 전달할 수 있는 테크닉
Instruction이 commit되면 programmer-visible state가 바뀜
HW의 측면에서 보면, superscalar processor는
- 필요에 따라 conditional branch의 결과도 예측 할 수 있는, 한번에 여러 instruction을 읽을 수 있는 fetch unit
- register 값의 true dependence를 파악하고 이들의 값을 필요에 따라 가져올 수 있는 방법
- 여러 Instruction을 병렬적으로 issue(실행의 시작)할 수 있는 방법
-
여러 instruction을 병렬적으로 execute할 수 있는 자원.
- 여러 개의 pipelined functional unit들
- 동시에 여러 개의 memory reference를 처리할 수 있는 memory hierarchy
-
load/store로 메모리와 값을 서로 전달할 수 있는 방법과 dynamic하고 예측불가능한 memory hierarchy의 performance behavior를 지원하는 memory interface
- process state를 올바른 순서대로 commit하여 바깥에서 보기에는 sequential execution처럼 보이도록 하는 방법
을 구현하고 있어야 한다. 실제 시스템에서 각각은 독립적인 것들이 아니고, seamless하게 통합되어 있다.
Paper Overview
2장에서는 superscalar의 general problem인, 겉보기에는 sequential한 프로그램을 parallel하게 바꾸는 문제에 대해 다룬다.
3장에서는 전형적인 superscalar microprocessor에서 사용되는 구체적인 테크닉을, 4장에서는 세 가지 최신 superscalar processor를 소개하면서 그러한 테크닉들의 스펙트럼을 살펴본다.
5장에서는 결론을 제시하고 미래에 ILP의 발전 방향에 대해 다룬다.
2. Program Representation, Dependences and Parallel Execution

위의 코드를 working example로 삼음. (a)가 C 코드, (b)가 어셈블리로 컴파일한 버전.
ILP를 향상시키는 첫 단계는 control dependence를 극복하는 것
- 가장 간단한 control dependence는 PC의 계속 증가
- basic block 내에 있는 instruction들은 window of execution, 즉 parallel execution을 위해 고려되는 instruction들의 집합이라 할 수 있음 ($\because$ data dependence만 없으면 됨)
- 더 많은 parallelism을 위해서는 conditional branch에 의한 control dependence 또한 극복되어야
- 이를 위해 conditional branch의 결과를 predict해서 speculative하게 fetch/execution
- prediction이 맞는걸로 판명되면 instruction의 "speculative" 상태를 제거
- 틀린 것으로 밝혀지면 recovery를 통해 architectural state가 잘못 변경되지 않도록 해줌
같은 window of execution에 있는 Instruction들은 data dependence에 놓여있을 수 있음
- instruction들이 같은 reg/mem 위치에 접근할 수 있기 때문, hazard의 가능성
- 이상적으로는 true dependence(RAW)만 고려해도 되지만, parallelism의 정도를 더 높이기 위해서는 artificial dependence들도 해결해야 함
- WAR: 앞선 instruction이 register 읽기를 끝낼 때까지 쓸 수 없음
- WAW: 쓰기가 올바른 순서대로 이루어져야
Control/data dependence가 해결되면 instruction들은 issue된 후 병렬적으로 실행됨
- HW가 parallel execution schedule을 짜게 됨
- true dependence나 FU와 datapath의 HW 자원 제약 등을 고려해야 함
- architectural state를 execution이 끝나자마자 update하면 안됨
- parallel execution $\rightarrow$ instruction이 원래 순서와 다르게 끝나는 경우 발생
- speculative execution $\rightarrow$ 실행되지 않아야 할 instruction들이 실행되는 경우 발생
- $\therefore$ architectural status가 업데이트되어도 될 때까지 임시 상태로 존재
- 임시 상태에서도 dependent instruction들에게 값 제공 가능
- sequential model에서도 해당 instruction이 실행되었을 거라고 판별되는 순간 임시 값이 architectural state에 반영됨 (commit 또는 retiring)
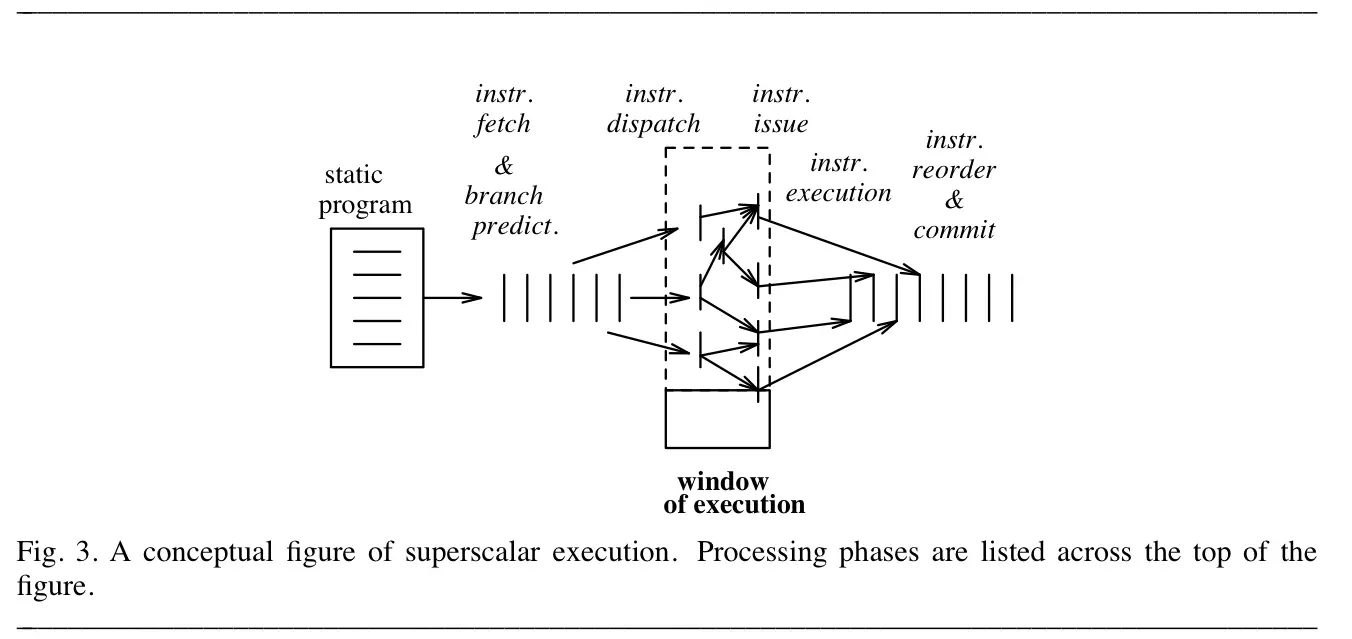
3. The Microarchitecture of a Typical Superscalar Processor
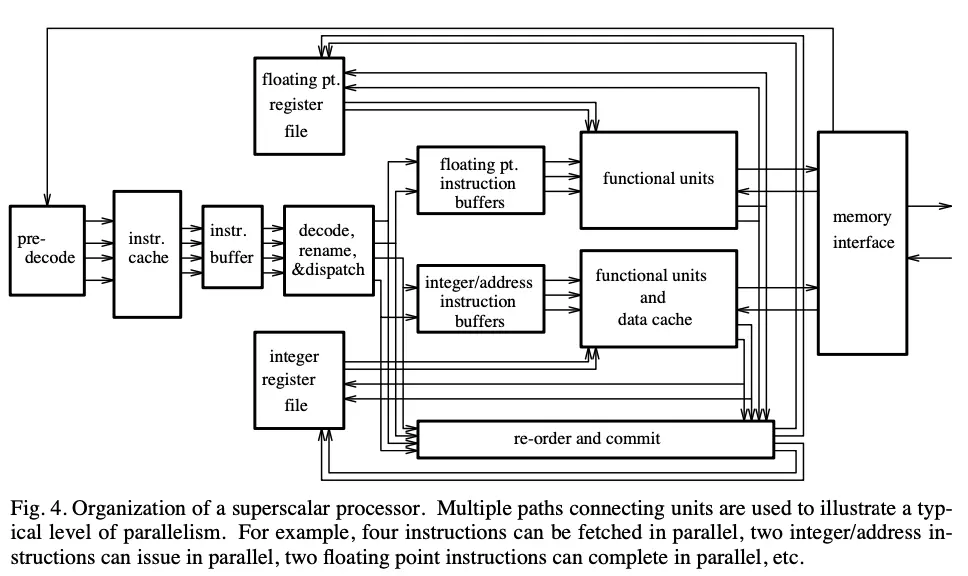
위는 일반적인 superscalar processor의 microarchitecture를 나타낸 것
- 주요 부분은 fetch, branch prediction, 디코딩 & 레지스터 의존성 분석, issue & execution, 메모리 연산 분석 & 실행, instruction reordering과 commit
- 위 디자인이 pipeline으로 구현돼있지만, 각각의 단계가 꼭 pipeline 단계와 일치할 필요는 없음
- issue width와 pipeline depth 사이의 trade-off가 존재 (깊이 다루진 않음)
3.1 Instruction Fetching and Branch Prediction
Instruction Fetching
Fetch 단계: instruction을 processor의 뒷부분에 공급해주는 역할
- instruction cache에 최근 사용된 instruction들을 저장. latency를 감소시키고 bandwidth를 높임
- 연속된 Instruction들로 구성된 block이나 line들로 이루어짐
- 한번에 block/line이 한꺼번에 cache에 들어옴
- CPI > 1을 유지하기 위해서는 매 사이클마다 여러 개의 instruction이 fetch되어야 함
- 이를 위해서는 i-cache를 따로 분리하는 것이 거의 필수적
- fetch BW는 적어도 peak decode/execution 속도 이상이어야 함.
- 남는 BW는 (1) i-cache miss의 경우나 (2) 최대 개수만큼 instruction이 fetch되지 않았을 때를 대비
- (2)의 예시: branch의 결과가 cache line의 중간에 있는 경우. 이럴 때는 2개의 cache line을 동시에 fetch하는 등의 테크닉이 나와 있음
- Cache miss나 branch에 의한 fetch의 불규칙성을 완화하기 위해 instruction (fetch) buffer를 도입하기도 함
- fetch가 지연될 때를 대비해 실행할 instruction들을 비축해놓음
Branch Prediction
- Branch는 fetch할 대상을 바꾸기 때문에 fetch의 지연을 유발함 -> 좋은 성능을 위해서는 branch prediction이 매우 중요
-
다음과 같은 단계로 수행됨:
- 해당 instruction이 conditional branch임을 인식
- branch outcome을 결정(taken/not taken)
- branch target을 계산
- (branch taken인 경우) instruction fetch로 control을 넘김
-
Conditional Branch의 인식
- pre-decoding: i-cache에 decode 정보가 미리 들어있으면 더 빠르게 conditional branch 여부를 파악할 수 있음
- extra bit 몇 개를 넣어놓는 식. i-cache의 전에 pre-decoding logic을 배치해 계산하게 함
-
Branch outcome의 결정(taken/not taken)
- branch가 그 앞에 있는 uncompleted instruction에 dependent한 경우 fetch 시에는 branch 여부 결정이 불가
- 이러한 경우 branch outcome을 predict
-
static methods: static binary만 보고 결정가능한 정보들을 이용
- e.g. 특정 opcode는 taken branch를 자주 발생시킨다든지, loop 때문에 backward branch가 더 잦다든지
- 컴파일러가 high-level code에 기반해, prediction을 위한 flag를 붙여주는 경우도 있음
- profiling information(이전 실행에서 수집한 통계 정보)를 이용하는 경우도
-
dynamic methods: run-time에 알 수 있는 정보들을 이용해 예측에 활용
- branch history(prediction) table: branch history를 저장
- branch instruction의 주소를 가지고 access
- 비트 몇 개 사용하여 최근 몇 번의 execution result를 저장하는 식
- prediction이 틀린 것으로 판명되면 IF는 실제 올바른 path로 redirect되고 틀린 경로의 실행 결과는 무효화
-
Branch Target의 계산
- branch target 계산은 주로 정수의 덧셈. PC + offset인 경우가 많기 때문
- 이 경우 register 읽을 필요가 없음. 다만 register를 branch target에 사용하는 경우도 존재
- branch target buffer를 도입해 최근에 branch가 향한 주소들을 저장하도록 하면 branch target computation을 더 빠르게 만들 수 있음
-
Control Transfer
branch take시 보통 한 cycle 이상의 딜레이가 발생 -> pipeline delay를 발생시킴
- 가장 일반적인 솔루션은 instruction buffer에 비축해둔 instruction을 이 때 실행하는 것
- 복잡한 buffer들은 taken/not taken 경로의 instruction들을 둘 다 비축해놓기 때문
- 초기 RISC 프로세서들은 delayed branch를 사용하기도 했음.
- 그러나 이는 pipelined structure에 대한 가정을 깔고 있으며 superscalar에서는 이러한 가정이 성립하지 않는 경우가 많음 -> 최근에는 사용 X
3.2. Instruction Decoding, Renaming, and Dispatch
insturction이 fetch buffer에서 나와 examine되고, control & data dependence 관계를 포착해 이후의 pipeline stage를 위해 set up되는 과정
- true dependence를 인식(RAW hazard 때문)
- register reuse에 의해 발생하는 다른 register hazard(WAR, WAW)를 해결
- FU에 연결된 buffer에 instruction을 보내는 dispatching도 여기에서 이루어짐
Decode 단계의 역할은 각 instruction에 대해 한 개 또는 여러 개의 execution tuple을 세팅하는 것
- (실행될 operation, 입력 operand가 위치하는/위치할 장소에 대한 정보, 결과가 저장될 장소)
Register Renaming
- WAW나 WAR hazard를 방지하기 위해서, 값이 저장되는 물리적인 장소는 논리적 대상(e.g. 레지스터 번호)과 다를 수 있음
- e.g. 같은 register name에 대응되는 여러 개의 물리적 저장 요소가 있을 수 있음
- instruction이 logical register에 값을 부여하면 해당 값에 HW가 알아볼 수 있는 이름이 할당됨, 뒤따르는 instruction들은 이 이름으로 physical storage location에 접근
- Figure 4의 "decode/rename/dispatch" 단계에서, execution tuple에 있는 register designator를 physical storage location으로 바꿔줌으로써 수행 (renaming)
- 크게 두 가지 방법이 있음
-
physical register file이 logical register file보다 큰 경우: mapping table로 동적으로 매핑
- mapping table이 서로 대응되는 logical/physical register 이름을 기록
- decode 단계에서 sequential order로 register renaming이 수행.
- free list에서 physical register를 하나 골라 대응시키고 mapping table을 업데이트
- physical register가 마지막으로 읽힌 후에는 free되어야 함
- 방법 중 하나는 counter를 사용하는 것.
- source register가 해당 physical register로 rename될 때마다 counter를 증가, 실제 issue되어 읽기가 일어날 때마다 counter를 감소. counter=0이 되면 free
![[The Microarchitecture of Superscalar Processors-20240926210844806.webp|605]]
-
physical register file이 logical register file과 같은 크기인 경우: 둘 사이 대응관계가 고정됨, 그러나 reorder buffer로 renaming을 함.
- e.g. logical $r13는 무조건 physical RF의 13번째에 대응
-
reorder buffer: active instruction(dispatch됐지만 commit되지 않은 것)마다 한 개씩의 entry가 존재.
- FIFO queue처럼 작동. precise interrupt를 위해 reordering하는 역할도 하기 때문에 이렇게 명명
- instruction은 dispatch시마다 ROB의 끝에 entry를 할당받음, 실행이 끝나면 ROB entry에 result를 기록
- ROB의 head에 도달한(=앞의 inst들은 다 이미 commit) instruction이 실행 끝나면 ROB entry는 지워지고, 기록해뒀던 실행 결과를 register file에 씀
-
Logical register의 값은 physical register에 있을 수도 있지만, reorder buffer에 있을 수도 있음.
- 이 경우 mapping table이 해당 logical register의 값이 physical RF에 있는지, 없다면 reorder buffer의 어느 entry에 있는지 알려줌
- reorder buffer가 가득 차면 dispatch는 일시 중단됨
![[superscalar_fig7.webp|468]]
Fig. 7은 add r3, r3, 4가 어떻게 rename되는지 보여줌
- mapping table은 각 reg 값이 physical RF에 있는지 ROB entry에 있는지 알려줌
- 현재 r3에 쓰는 instruction이 실행되고 있는 상황 -> r3의 값은 physical RF가 아닌 ROB6에서 읽어옴
- 결과가 나오면 r3뿐만 아니라 (현 instruction이 대응되는) ROB8에도 써줘야 함
두 방법 모두 artificial dependence를 해소 -> WAW와 WAR hazard를 방지.
$\therefore$ RAW dependence만 처리하면 됨
3.3. Instruction Issuing and Parallel Execution
앞선 단계(decode/rename dispatch)에서 execution tuple이 만들어졌음
- 이제 어느 tuple을 issue할지 결정해야 함
- issue: 데이터와 자원의 availability를 run-time에 확인하는 것
이상적으로는 input operand가 전부 도착시 바로 issue되어야 함
- 그러나 execution unit, interconnect, register file port 등 물리적 자원의 제약이 있음
- 또 execution tuple을 저장하는 buffer의 organization에 의한 제약들이 있음
- reservation station 말고 queue 형태로 만들면 앞에 있는 instruction들을 먼저 issue해야 하니까
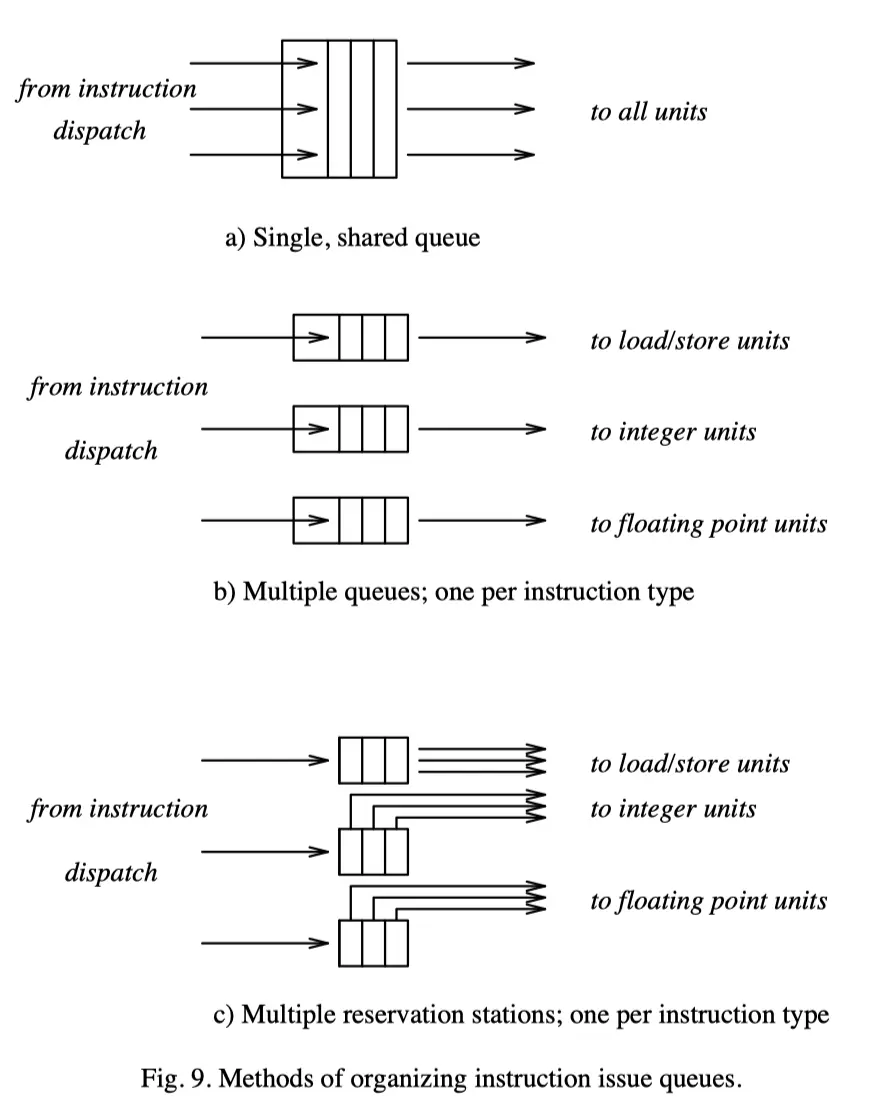
간단한 것부터 instruction issue buffer의 구성 방법을 소개함
-
Single Queue Method
- 하나의 queue로 모든 functional unit에 명령어를 배분.
- FIFO queue 하나가 끝이므로 out-of-order 실행이 불가능 -> register renaming을 할 필요가 없음
- operand의 가용 여부는 reservation bit 하나로 확인이 가능.
- 해당 register에 쓰고 있는 Instruction이 있으면 reserved, 해당 instruction이 끝나면 clear
- operand 중 reserved인 것이 없으면 issue가 가능함
-
Multiple Queue Method
- 각각의 queue에서는 in-order로 issue됨. 서로 다른 queue끼리는 순서가 바뀔 수 있음
- 어느 queue에 들어갈지는 Instruction type에 따라 분류됨. queue는 각 FU에 대응되기 때문
- register renaming은 제한적인 형태로만 가능함. 예를 들어, load의 대상이 되는 register만 rename되는 식
- load operation이 다른 instruction들보다 앞으로 감으로써 해당 값이 필요하기 전에 memory data를 미리 읽어오는 것이 가능해짐
-
Reservation Station
- Tomasulo's algorithm의 일부로 처음 제안됨. FIFO ordering 없이 out-of-order로 issue됨.
- operand availability를 각각의 reservation station이 계속 체크해야 함
- RS로 instruction이 dispatch될 때,
- 이미 가용한 operand는 값을 그대로 가져와 entry에 넣음
- 그렇지 않은 operand는 끝나는 instruction들의 result designator들과 비교
- 내부에서 instruction type에 따라 partition되어 있을 수도, 단일 저장소에 저장될 수도 있음
- 최신 RS들은 실제 source data를 저장하지 않고 저장 장소를 가리키는 pointer로 저장.
- e.g. register file 또는 ROB entry

3.4. Handling Memory Operations
Memory operation은 superscalar에서 특별한 취급이 필요
- latency를 줄이기 위해 memory hierarchy가 도입
- 대부분의 data는 d-cache로부터 공급될 것이라 기대 가능
- 보통 primary cache는 프로세서와 같은 칩에 놓음
- 접근될 operand가 무엇인지 decode단계에서부터 알 수 있는 ALU 연산들과는 달리, memory 연산들은 접근될 memory location이 어디일지 issue 단계 이전에는 알 수 없음
- 정수 덧셈으로 주소를 계산해야 하기 때문
- 주소 계산 후에는 physical address로 변환하기 위해 translation이 필요.
- Translation Lookaside Buffer(TLB) 가 cache와 같이 개입해 이 과정을 가속화
- 이렇게 유효한 주소가 구해지면 load/store 연산이 메모리로 보내짐
- 실제로는 address translation과 memory(cache) access가 동시에 실행됨
- 일단 address translation과 동시에 cache에 접근
- 어차피 address의 subset으로 접근하니까 내가 찾는 주소가 아닐수도 있음
- translated address가 끝난 이후에, 실제 cache tag와 비교해 방금의 접근이 hit인지(즉 내가 찾는 데이터가 맞았는지) 판별
시간을 줄이기 위해서는
- (1) latency 자체를 줄이거나, (2) 메모리연산끼리 혹은 메모리연산과 다른 연산을 parallel하게 실행하거나, (3) 메모리 연산이 out-of-order로 실행될 수 있게 하는 것이 필요
- 그러나 memory location은 register의 개수보다 훨씬 많기 때문에 이전 장에서 register에 대해 적용했던 방법들은 적용 불가능
- renaming 등은 memory location 중 현재의 working set에만 적용하면 됨
- i.e. 현재 pending memory operation이 있는 위치들에 대한 정보만 저장하고, 필요시 이들을 associative하게 검색
Multiport
- 한 사이클에 memory operation 한 개만 허용하는 superscalar processor들도 있으나, 이는 점점 더 bottleneck으로 작용
- 한 cycle에 여러 memory 접근을 허용하려면 multiported이어야 함
- 일반적으로는 hierarchy의 최하위 계층(= primary cache)만 multiport로 하면 충분함.
- 상위 계층까지 도달하는 request는 잘 없기도 하고
- level들 간의 데이터 교환은 line 단위로 이루어지기 떄문
- Multiport의 구현 방법: (1) multiported storage cell을 사용 (2) 여러 개의 memory bank (3) 한 사이클 안에서 순서대로 여러 개의 요청을 보내기
Non-blocking
메모리 연산과 다른 연산의 overlapping을 허용하려면 hierarchy가 non-blocking이어야 함
- i.e. d-cache miss가 나면 데이터 가져오는 동안 다른 instruction이 먼저 실행되어야 함.
- 다른 memory request들도 여기에 포함
Store Address Buffer
Memory operation들이 overlap되거나 out-of-order로 실행될 수 있도록 하려면
- hazard들이 올바르게 처리되고
-
sequential execution semantics가 보존되어야 함
store address buffer는 memory request의 hazard를 감지해 막는 역할
-
pending중인 store operation들을 전부 저장하고 있다가,
- load/store operation이 issue되려고 하면 같은 주소로의 pending store가 있는지 확인함
Memory hierarchy로 요청이 전송되면, d-cache hit 또는 miss가 발생할 수 있음
- miss시 해당 위치를 포함하고 있는 data line이 cache로 fetch됨
- 이 line의 위치에 대한 접근은 fetch가 완료될 때까지 기다려야겠지만, 다른 위치로의 접근은 기다리지 않고 먼저 실행이 가능
- Miss Handling Status Registers(RHSRs): 해결중인 cache miss의 상태를 트래킹하고, memory hierarchy로의 여러 요청이 overlap될 수 있게 handling하는 역할
3.5. Commiting State
instruction의 lifetime에서 마지막은 commit 또는 retiring이라고 불리는 과정
- instruction의 효과가 logical process state를 바꾸는 것이 허용됨
- 실제로는 (매우) non-sequential한 내부 동작을 감추고, sequential model처럼 보이도록 함
Commit 단계에서 해야 할 일은 precise state를 구현하는 방법에 따라 달라짐
- precise state의 구현을 위해서는 (1) operation의 실행에 따라 update될 state (2) recovery를 위한 state를 둘 다 저장하고 있어야 함
- 크게 두 가지 테크닉이 있음
-
machine state를 history buffer 또는 checkpoint라는 곳에 백업해놓기
- 즉 백업을 계속 해놓는거 말고는 특별한 일을 하지 않음
- precise state가 필요한 시점이 오면 history buffer에서 꺼내와 복원하면 됨
- 이 경우, commit state에서는 더 이상 필요 없는 history state들을 삭제해주는 일만 하면 됨
-
machine state를 둘로 나눔: implemented physical state와 logical (architectural) state
- physical state: 명령어가 완료되면 즉시 업데이트되는 상태
- architectural state: sequential model로 실행된다고 가정 시에 업데이트되는 상태
- 즉, instruction에서 "speculative" 태그가 떼지고 확정된 명령어들의 결과를 프로그램 순서대로 반영
- speculative state(즉 speculative execution의 결과물)를 ROB에서 관리함
- commit시에는 instruction의 결과가 ROB에서 architectural RF로 옮겨지면서 ROB entry가 할당해제됨
- 마찬가지로 store instruction인 경우 ROB에 있던 store data가 메모리에 옮겨짐
ROB는 renaming의 physical register method에서도 사용된다
[[#3.2. Instruction Decoding, Renaming, and Dispatch|3.2절]]에서 register renaming을 살펴보면서, ROB method(2번)을 알아보았음
- 그러나 physical register method (1번)에서도 ROB가 유용하게 사용됨
- physical register method의 경우 값들은 ROB가 아닌 physical register로 바로 쓰이긴 함
- 그러나 ROB는 control이나 interrupt information 또한 가지고 있음.
- commit시 이를 사용해 physical register를 free list에 넣음
- interrupt가 발생할 시, control information은 logical-to-physical mapping table을 변경하여 올바른 precise state를 반영할 수 있도록 함
3.6. SW의 역할
최적화된 binary는 같은 일을 더 빠르게 처리할 수 있음.
4. Three Superscalar Microprocessors
위에서 살펴본 바를 바탕으로 최신 superscalar processor들을 살펴봄
- MIPS R10000: 위에서 살펴본 것과 같은 전형적인 구현
- DEC Alpha 21164: 더 간단한 구조
- AMD K5: x86 기반
4.1. MIPS R10000
위에서 설명한 것과 매우 유사한 구조로, dynamic scheduling을 많이 함.
- 사실 위의 그림4가 MIPS R10000을 바탕으로 그린 것
- fetch 단계
- 매 사이클 4개의 insturction을 i-cache에서 fetch
- cache에 들어갈 때 pre-decoding되어 4개의 추가 bit가 fetch 즉시 instruction type을 알 수 있게 도와줌
- branch prediction이 수행
- instruction cache와 맞춰서 512개의 entry를 가진 prediction table을 사용
- 각 entry는 2-bit counter로 prediction 만들어냄
- branch가 taken으로 예측되는 경우 instruction fetch를 redirect하는 데 한 cycle이 필요
- 이동안 not-taken path에 있는 instruction들을 fetch해 resume cache에 넣음
- resume cache에는 4개의 block까지 들어감 -> 동시에 4개의 branch prediction 가능
- decode/rename/dispatch 단계
- decoding은 predecoded bit 덕분에 조금 더 간단해짐
- R10000은 physical RF(64개)가 logical RF(32개)보다 2배 큼 -> 모든 register designator는 rename됨
- dispatch 단계
- 한 번에 최대 4개의 instruction이 dispatch 가능
- instruction queue가 3개: memory, integer, floating point
- dispatch시 각 physical register의 reservation bit은 busy로 설정
- integer/FP FU는 FIFO 순서로 issue하지 않음(따라서 queue라는 말은 조금 맞지 않음)
- queue entry는 reservation station에 가깝게 행동.
- 그러나 value field나 valid bit가 있지는 않음. 대신 physical register designator를 가지고 있음.
- queue에 있는 각 instruction은 자신의 source operand에 해당하는 register reservation bit을 보고 있다가, 모든 register가 not busy 될 때 issue함
- memory queue의 경우 instruction을 오래된 순서로 처리하도록 돼있음 -> address hazard의 감지를 단순화
- 다른 queue들은 strict하게 오래된 순서대로 처리하진 않음
-
functional unit
- 5개의 FU가 있음. address adder, integer ALU $\times$ 2, FP multiplier/divider/square-rooter, FP adder
- 이때 ALU 두개는 서로 다름. 덧셈, 뺄셈, 논리 연산은 다 할 수 있지만 하나는 shift/하나는 곱셈이 가능
-
Cache
- on-chip primary data cache와 off-chip secondary cache를 가지고 있음.
- primary cache는 second cache miss에만 blocking함
-
Reorder buffer
- 동시에 4개까지 commit이 가능함(program order로)
-
commit 시, 기존에 destination (logical) register에 묶여있던 Physical register는 free해줌 (위의 renaming 설명에서 non-ROB (R10K) 방식에 나왔던 설명 그대로)
-> 새로운 physical copy가 architecturally precise한 새로운 버전이 됨
-
아직 commit 안된 Insturction의 exception 정보는 ROB에 저장됨. excepting insturcion이 commit되려고 하면 Interrupt가 발생함
- interrupting instruction의 다음 instruction에 붙어있는 정보가 logical-to-physical mapping을 재조정해 logical state가 Interrupting insturction과 일관되도록 함
- 예외 발생 이후의 instruction들이 이미 실행되어 physical register 값들을 바꾸었을 가능성이 있기 때문에, 이를 복구해주는 것
- branch recovery
- branch prediction시 processor는 register mapping table의 snapshot을 찍음.
- misprediction이 발견되면 이 때의 register mapping이 빠르게 복원
- resume cache에 저장해놓은 instruction들을 이용하여 instruction processing을 바로 다시 시작할 수 있음
4.2. Alpha 21164
![[superscalar_fig12.webp]]
- 더 높은 clock를 위해서 dynamic instruction scheduling의 이점들을 포기하고 간단하게 구현
- Fetch
- 매 사이클에 4개의 instruction을 i-cache에서 fetch
- 두 instruction buffer(각각 size 4) 중 하나에 들어감.
- instruction들은 각 buffer에서 program order로 issue됨. buffer가 완전히 비어야 다음 buffer가 사용됨
- Branch Prediction
- branch prediction은 i-cache와 associate된 branch table을 이용해서 일어남
- cache의 각 instruction에 대한 branch history entry가 있음. 각각 2bit counter
- 한번에 1개의 unresolved predicted branch만이 있을 수 있음
- predict한 path에서 또 branch 만나면 그냥 stall됨
- Issue
- Fetch/decode 후 instruction type에 따라(i.e. FU에 따라) 분류됨
- operand data가 전부 준비되면(register에 있든 bypass가 가능하든) issue됨
- 이 과정에서 instruction간의 새치기는 불가능. �i. e. out-of-order가 아님!
- Fig 9a에 있는 single queue method에 해당
- Functional Units
- 2 x integer ALU, FP adder, FP multiplier. 총 4개
- integer ALU는 서로 다름. 하나는 shift/multiply가 가능한데 비해 나머지 하나는 branch evaluation이 가능
- Cache
- 2-level cache가 on-chip에 존재.
- i-cache와 d-cache가 primary cache로 존재하고, instruction과 data에 모두 사용되는 secondary cache가 따로 있음
- primary cache는 여러 개의 miss를 견딜 수 있음.
- 6-entry Miss address file(MAF)이 있어서 load miss에 대해 address와 target register를저장해둠
- 같은 cache line에 있는건 하나로 합치기 때문에, 실제로는 6개보다 많은 cache miss를 저장할 수 있음
- Interrupt 처리
- 애초에 out-of-order로 실행을 하지 않음
- pipeline의 마지막 단계가 register file을 원래 program-order대로 업데이트함
- 대신 bypass가 있어서 commit되기 전의 값들도 사용이 가능함
- pipeline 전체가 reorder buffer의 (reordering을 제외한) 역할을 대신하는 셈
- 다만 floating point instruction들은 out-of-order로 file을 업데이트 할 수 있음 -> FP exception은 precise하지 않음
4.3. AMD K5
나머지 둘과는 달리 x86으로 구현 -> fast, pipelined implementation을 염두에 둔 ISA가 아님!
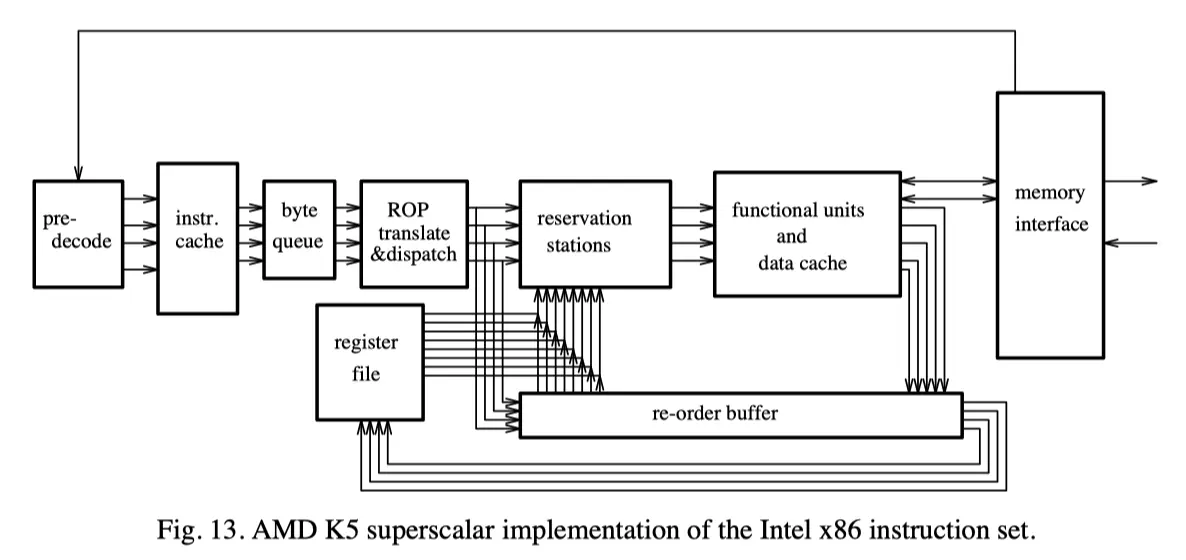
- Fetch
- variable length이므로 이전 instruction이 decode되어야 다음 instruction을 찾을 수 있음
- 때문에 i-cache에 올릴 때 pre-decoding을 수행함
- 매 instruction byte당 5개의 pre-decode bit이 있음
- 해당 byte가 instruction의 시작이나 끝인지/opcode나 operand인지 등을 알려줌
- i-cache에서 사이클당 16바이트가 fetch됨 -> byte queue에 넣어놓음
- instruction이 variable length니 이렇게 부르는듯
- Branch Prediction
- 앞서 소개한 두 프로세서와 마찬가지로, i-cache와 묶어서 branch prediction을 수행함
- cache line마다 한 개의 prediction
- 이전 실행에서 해당 branch가 어떻게 됐는지를 1bit로 기록하
- 또 target instruction으로의 pointer 또한 저장해놓음
- i-cache의 어디에서 fetch해야 하는지를 알려줌으로써, predicted target instruction을 fetch하는 시간을 줄임
- Decoding
- CISC의 복잡성 때문에 2 cycle이 걸림
- 사이클 1에서는 byte queue로부터 byte들을 읽어와 RISC-like operation으로 변환
- 최대 4개의 ROP가 생성됨.
- 만약 x86 instruction이 단순한 거라면 ROP 1개만으로 충분한데, 이 경우 사이클 1에서 끝남
- 복잡한 instruction은 사이클 2를 거침.
- ROM에 순차적으로 lookup하여 ROP들로 변환
- ROP로 변환하고 나서는 기존의 x86 instruction들은 별로 중요하지 않음
- Dispatch
- 변환된 ROP들은 FU의 reservation station들로 dispatch됨
- operand가 준비되지 않았다면 reservation station에서 기다림
- Functional Unit
- 2x integer ALU, FP unit, 2 x load/store unit, branch unit. 총 6개
- ALU 중 하나는 shift들, 하나는 integer 나눗셈을 담당
- FP unit을 제외하고 나머지는 각각 2개씩의 reservation station을 가짐
- 4 ROP issue/cycle을 지원하기 위한 충분한 register port와 data path가 있음
- Cache
- 4-bank data cache가 있음
- 서로 다른 bank로는 동시에 load/store가 가능. 같은 bank로는 같은 cache line일 때만 동시 접근 가능
- Reorder Buffer
- 16-entry ROB. exception 시 precise state를 유지하게 도와줌
- associative lookup을 통해 data가 준비되었는지 확인 후 bypass
- P6 방식(ROB 방식)의 renaming을 하므로 이를 도와줌
- Reorder buffer는 branch recovery에도 사용됨
5. Conclusion: What Comes Next?
Superscalar model은 성능과 호환성이 모두 중요.
- 전혀 sequential하지 않음에도 sequential execution model을 구현함
- true dependecne들만 남겨놓고 instruction stream을 조각내어 병렬로 실행.
- 그러면서도 원래의 sequential order에 대한 정보를 보존해 precise interrupt를 구현
Parallel hardware가 추가 투입 시에는 "한계효용이 체감"될 수밖에 없음
- 아무리 aggressive한 방법을 써도 ILP에는 한계가 있음
- 특히 conditional branch의 영향이 큼. prediction을 아무리 잘 만들어도, prediction이 완벽한 경우의 가정과 비교시 큰 성능 차이가 발생
- 동시에 issue되는 instruction의 개수가 증가할 때마다 HW의 complexity가 크게 증가
- data path(FU 개수, register와 cache port 등)가 복잡해지는 것은 당연
- 동시에 dispatch, issue되는 insturction간의 cross-check로 인해 control complexity 또한 quadratic하게 증가
- 이는 결국 clock period에 영향
System level issue들
- memory와 processor의 속도 gap이 점점 벌어짐
- 더 섬세한 d-cache design, prefetch method, 더 발전된 memory hierarchy, memory chip design 등의 방법
혁신적인 새로운 방법이 나오지 않는다면, 8-way superscalar 정도가 실질적인 한계일 것으로 생각됨. 그 다음은 어디인가?
- VLIW
- sequential execution model에서 출발한 것. instruction에서 다음 instruction으로 차례대로 실행
- 컴파일러가 알아서 parallel execution schedule을 만들어주어야
- 두 가지 장점
- superscalar processor보다 parallelism을 쥐어짤 수 있는 instruction window가 더 넓음
- control logic에서 dependence checking을 할 필요가 없으므로 구현이 더 쉬움
- 단점
- run-time에 이루어지는 다양한 상황을 반영하지 못하고, 정해진 실행 순서에 의존하므로 최적화에 한계
- Single flow of control로부터의 탈피
- 여러 개의 PC로 instruction을 fetching하면, parallel execution을 위해 더 다양한 instruction을 선택할 수 있음
- multiprocessing
- high-level program의 자동 병렬화가 이미 슈퍼컴퓨터에 사용되고 있음
- 다중 프로세서가 fine-grained ILP를 활용하려면 프로세서간의 동기화나 통신을 위한 overhead가 더 낮아져야 함
- statical하게 program을 병렬화시키려면 compiler support가 많이 필요할 것