
This article summarizes Chapter 4. Superscalar Organization of Modern Processor Design, Shen, P. S. and Lipasti, M. H.
Superscalar processors are machines that can process more than 1 instructions per cycle in average. These machines achieve this performance typically by employing parallel pipelines and out-of-order execution. This chapter goes through the considerations in organizing a superscalar processor.
1. Limitations of Scalar Pipelines
Rigid scalar processors, which can execute only one instruction in a cycle, have three inherent limitations as follows:
- The maximum throughput is bounded by IPC = 1.0.
- There arises inefficiency since all the instructions of different types go through the same pipeline.
- A stalled instruction causes all the following instructions to be stalled together.
2. From Scalar to Superscalar Pipelines
These limitations can be overcame by the techniques used in superscalar processors. To begin with, we can achieve IPC greater than 1 by initiating the execution of more than one insturctions in a cycle, by employing parallel pipelines. In such parallel machines, each pipeline consists of different functional units, which can be customized to process different kinds of instructions. For example, the pipeline in the figure below (Figure 4.5) has four functional units each in charge of integer ALU, memory, floating-point arithmetic, and branch operations. This case, all the instructions experience only necessary latency. Also, if the dependency between the instructions is resolved in prior, the instructions do not go through further stalling.
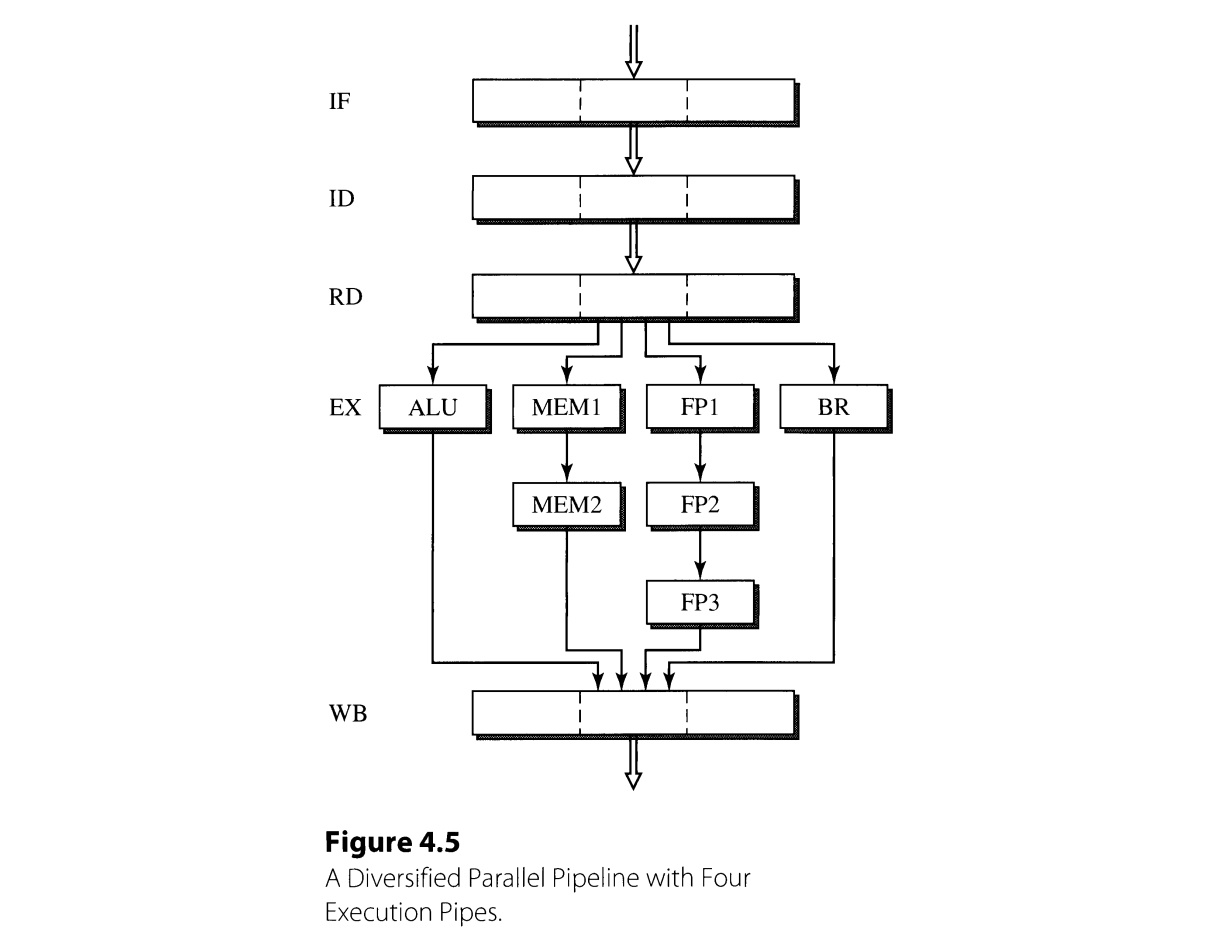
The buffers, which are basically clocked registers, between the pipeline stages can be improved to implement a superscalar pipeline. The parallel pipeline necessitates a buffer with multiple entries, namely, a multientry buffer. A multientry buffer itself is nothing more than a collection of buffers, but one can enhance its behavior in various ways as follows:
- Implementing shift-register like logic enables the buffer to work as FIFO queue.
- Allowing independent accessing of each entry makes the buffer resemble a small multiported RAM.
- Implementing associative accessing allows the access to the content by its values.
Superscalar processors use these complex buffers as dispatch buffer, which stores instructions to be executed. This makes the out-of-order issuing (i. e., begin the execution) possible, allowing a trailing instruction to get over the prior stalled instruction. However, the instructions must finish in order to guarantee the proper handling of exceptions. Therefore, another multientry buffer called the completion buffer must be employed to reorder the instructions that have finished the execution. These pipelines that support out-or-order execution are called dynamic pipelines.
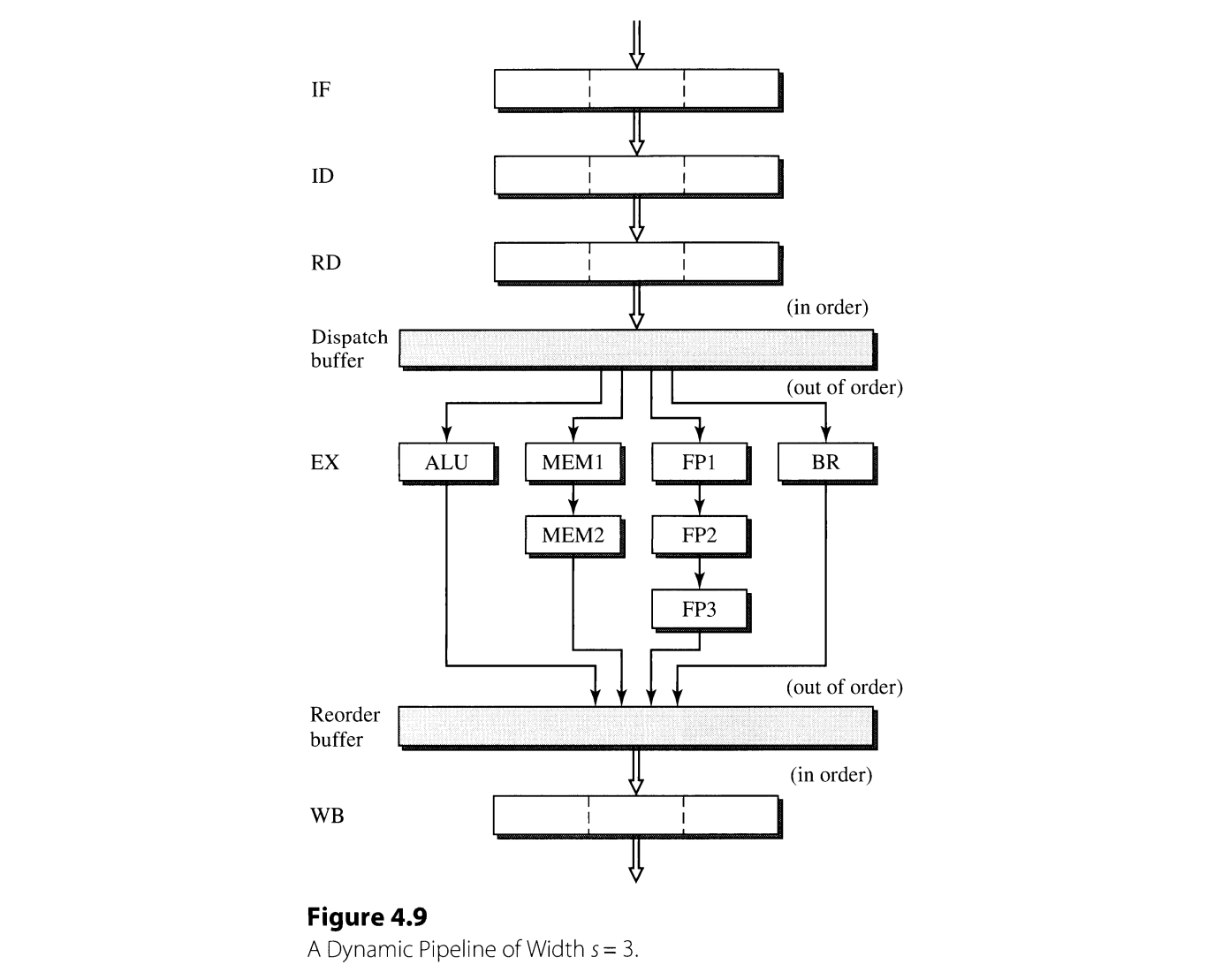
3. Superscalar Pipelines Overview
The book introduces a six-stage superscalar pipeline, TEM, as a motivating example. The six stages of the pipeline are called fetch, decode, dispatch, execute, complete, and retire.
- dispatch stage distributes the instructions to according functional units
- complete stage reorders the instructions to update the machine state in-order.
The section goes through the techniques employed in each stage to implement a superscalar processor.
3.1. Instruction Fetching
The fetch stage of a parallel pipeline with width $s$ must be able to simultaneously fetch $s$ instructions from I-cache in a cycle. A cache line width of the I-cache may be identical to $s$, or a multiple of $s$.
There are two challenges in achieving the maximum throughput of fetching $s$ instructions per cycle: misalignment and control flow-changing instructions.
Misalignment
The fetch group, the block of instructions that are fetched together, can be misaligned with respect to the cache line. This case, when the fetch group lies over two cache lines, not all $s$ instructions can be fetched in a single cycle. There are two kinds of solutions that are used to cope with misalignment problem: software solution and hardware solution.
Software solutions can be applied in compile time, transforming the code to ensure appropriate alignment. For example, every instruction that can be a target of a branch must be placed in the starting position of a fetch group. However, the solution is too specific to I-cache and can increase the code size.
Hardware solutions, in contrast, works at run time. The solution is implemented by employing an additional alignment hardware. One of the examples is that included in IBM RS/6000 machine. the I-cache of RS/6000 is a two-way, four-set cache where four subarrays are in charge of storing instructions in address $4k, 4k+1, 4k+2$, and $4k+3$, respectively. Once the fetch logic detects that the starting address of the fetch group is not divided by 4, what is denoted as “T-logic” automatically increases the row number of subgroups. For example, if the starting address takes the form of $4k+2$, the subgroup 0 and 1 will be fetching $4(k+1)$ and $4(k+1) + 1$, instead of $4k$ and $4k + 1$. The fetched instructions are further rotated by the instruction buffer network. As a result, the device can always fetch four consecutive instructions from an arbitrary address.
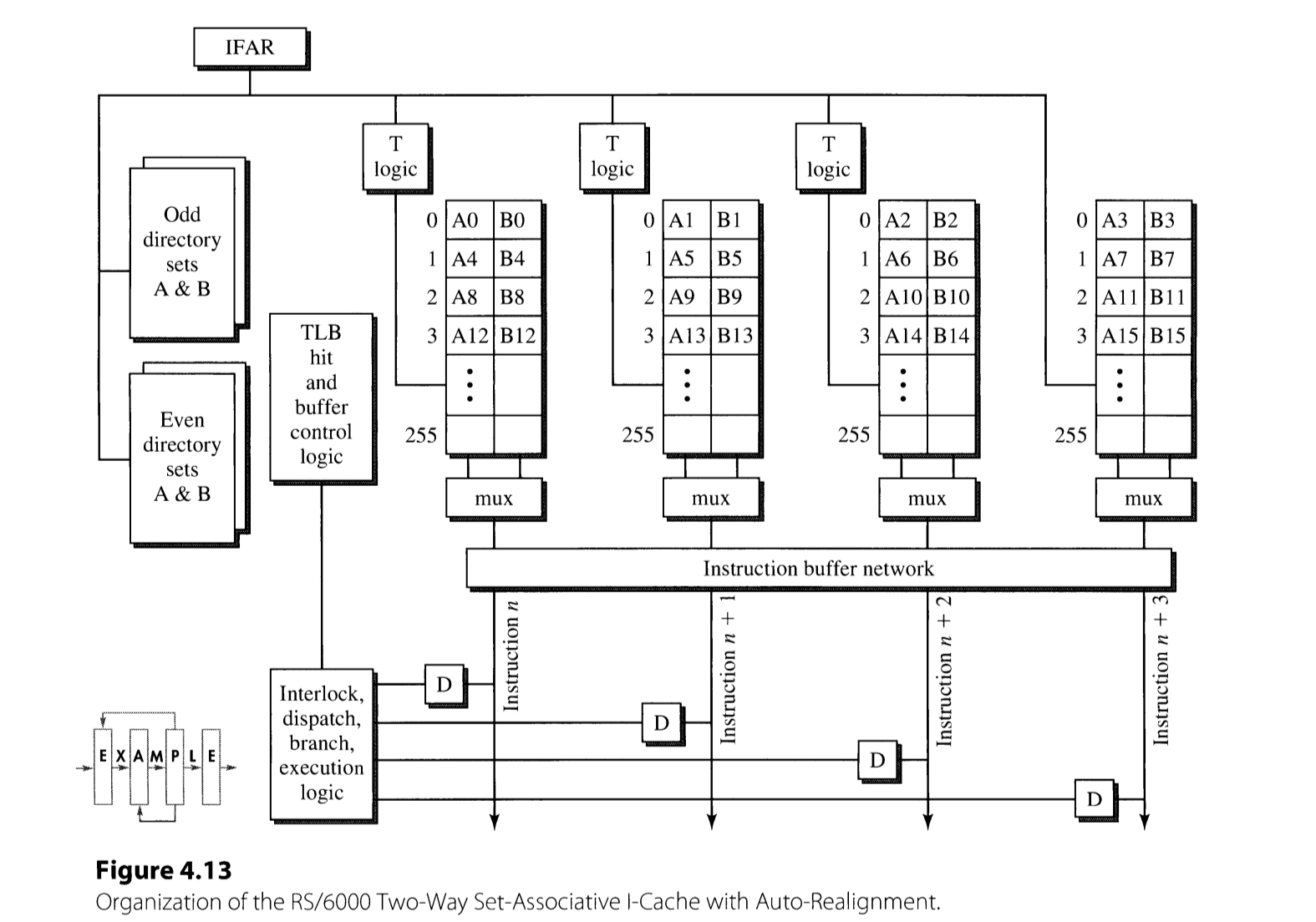
Branches
Control flow-changing instructions, or simply branches, make the already fetched instructions following them to be useless. The solutions to mitigate the performance degradation caused by branches are introduced lated in the book.
3.2. Instruction Decoding
The complexity of decoding stage differs a lot by the ISA and the width of parallel pipelines. CISC processors have much more complicated decoding logic by two reasons:
- Instruction translation logic is needed to degrade the instruction words into lower-level microoperations(μOPs). These are the instructions that are actually executed in the rest of the pipeline.
- Variable lengths of instruction turns the decoding process into a sequential task.
Decoding stage in CISC
The decoding process of Intel Pentium Pro is demonstrated as a prime example. Three decoders — a generalized decoder and two restricted decoders — composes the overall logic. The generalized decoder always generates at least 1 μOP to 4 μOPs at most, while the other two restricted decoders may or may not generate one μOP. The goal of restricted decoders is to try translating the instructions following the instruction decoded by the generalized decoder, which may fail if the instruction is relatively complicataed. Generalized decoder, in contrast, can translate the instruction no matter how complex, although it may take several cycles.
Predecoding
As decoding process becomes more complicated, branch miss penalty may also increase. To prevent the decoding logic being undesirably complex, predecoding can be implemented when I-cache loads a new data. This case, instructions are partially decoded before it is loaded to the I-cache and a few bits are stored together with the instructions. Despite its effectiveness, predecoding may cause overhead since it increases the I-cache miss penalty and enlarges the I-cache size. Therefore, there is a trade-off in increasing the aggressivenss of predecoding. Although it is more prevalently used in CISC processors, predecoding can also be employed in RISC machines.
3.3. Instruction Dispatching
Instruction dispatching is a task of distributing instructions to appropriate functional units. The stage can be considered as the watershed between the earlier stages of centralized fashion and the later stages of multiple pipelines in distributed fashion.
Dispatcher requires a temporary buffer of instructions, the reservation station, borrowing the terminology of Tomasulo’s algorithm. This is because the operands of incoming instructions may not be available, necessitating a device to store them temporarily. This enables instructions with operands that are ready to overtake the stalled instructions, i. e. out-of-order execution.
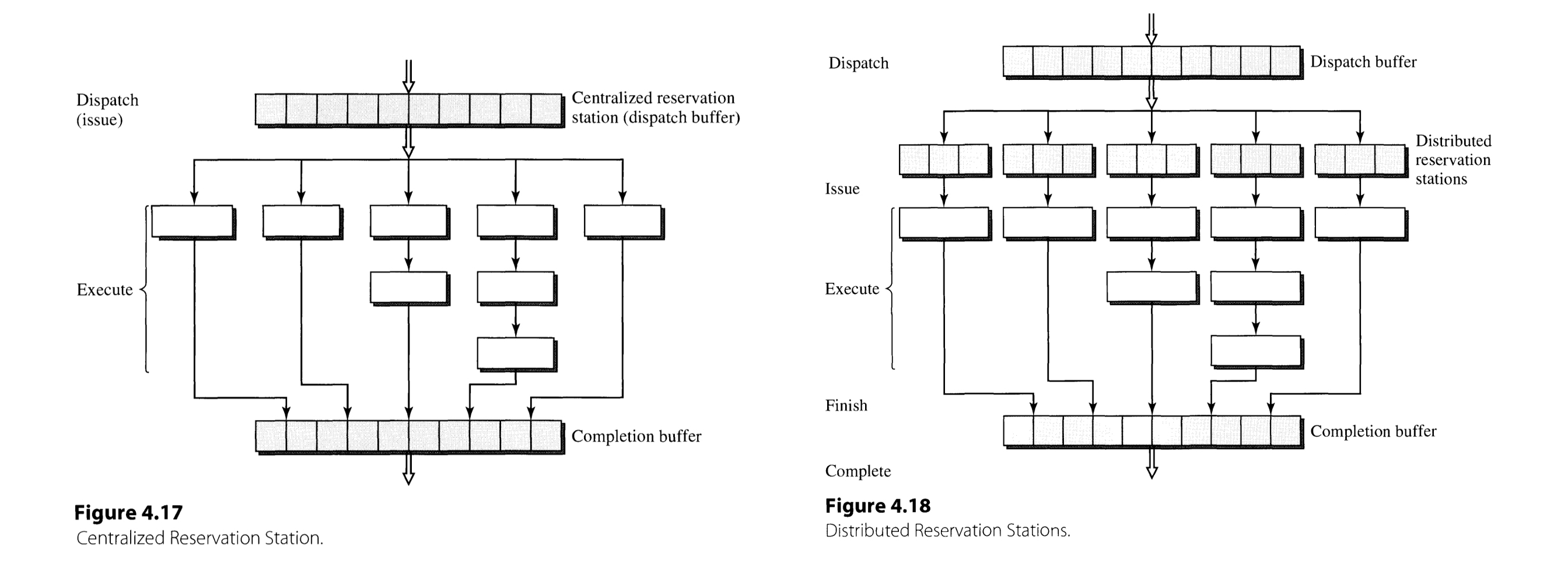
Reservation stations can be implemented either in centralized and distributed manner (Figure 4.17 and 18). The difference between the two types of implementation is whether there is a single, centralized reservation station, or each functional unit possesses its own reservation station.
The definition of dispatch stage may differ by book. In this book, dispatching means to associate the instruction with functional unit, while issuing implies the initiation of execution in functional units. Although the two terms can be used interchangeably for centralized reservation stations, the two process do not occur simultaneously and thus do not mean the same in distributed case.
3.4. Instruction Execution
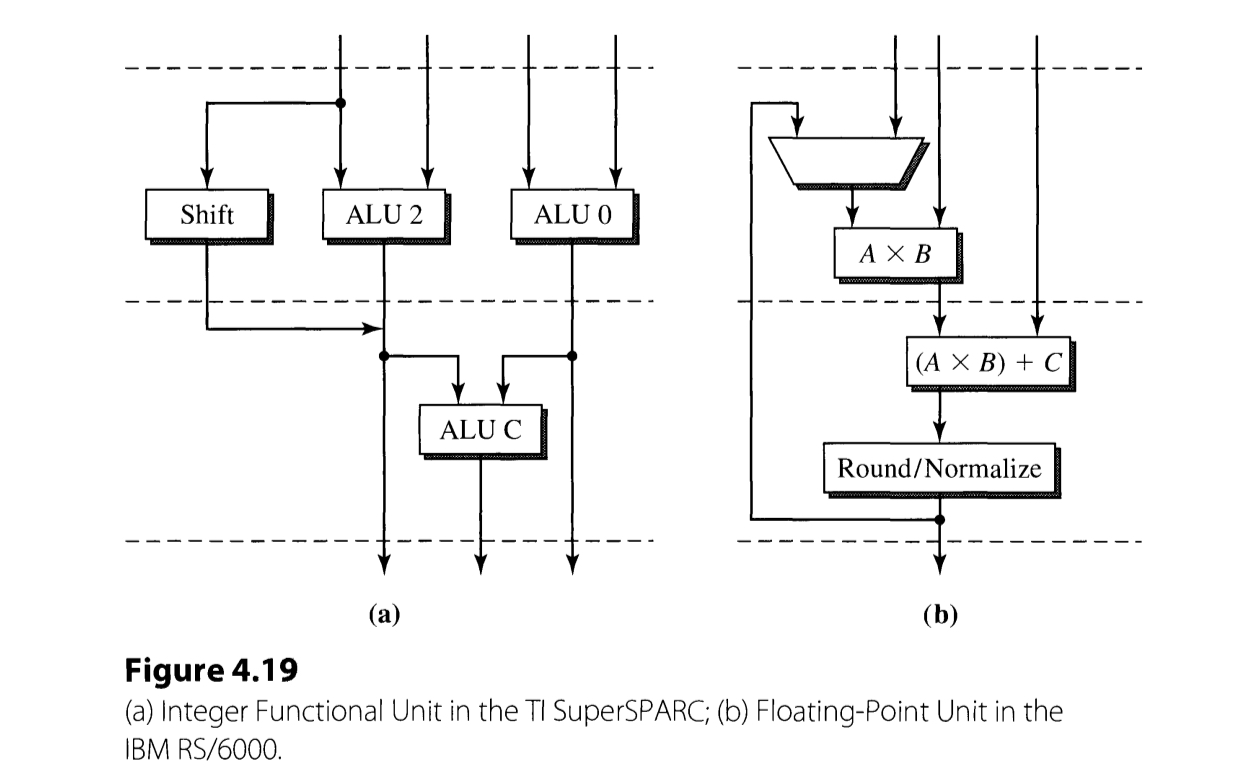
The figure above depicts the structure of integer and floating-point functional unit of RS/6000. Following are the interesting facts in execution stage of the pipeline.
- Compilers can be designed to exploit the architecture of the unit that can perform multiple instructions in a single cycle.
- An integer unit can also be used for generating memory address and executing branch and load/store, although recent trend is to separate them as an independent pipe.
- Most of the time, only one load/store functional unit is incorporated, which is a small number considering the portion of load/store operations in a typical code. This is because this requires D-cache to be multi-ported, which is extremely complex to implement.
Determining the number and kinds of functional units in the execution stage involves multiple considerations. In many cases, the total number of functional units exceeds the actual pipeline width. This occurs because the distribution of each kind of instructions varies by and throughout the code, while the functional unit distribution is fixed.
3.5. Instruction Completion and Retiring
Completion means that an instruction has finished execution and the machine state is updated. This involves the entrance to the completion buffer. As opposed to finished ones, which implies that the result of execution may only reside in nonarchitected buffers, completed instructions have their results stored in architecture register.
In addition, an instruction is retired when it exits the store buffer and updates the D-cache, whereas completion involves the updating of the machine state.
During the execution of a program, interrupts and exceptions can occur and disrupt the normal program flow. A pipeline is said to have precise exception if the architectural state of the machine at the time when exception occurs is saved so that program can resume at that point. To support precise exception, it is necessary to guarantee that the completion of instruction obeys the program order. This is achieved by reorder buffer.
Reference
- Shen, John Paul, and Mikko H. Lipasti. “Superscalar Organization.” Modern Processor Design: Fundamentals of Superscalar Processors, Waveland Press, 2013, pp. 192-231.