During this semester's Scalable High-Performance Computing course, I worked on optimizing matrix multiplication using various libraries and APIs including pthread, OpenMP, OpenCL, CUDA. Also, in the final project, I was able to gain valuable experience accelerating deep learning model inference using a cluster of GPU nodes, contemplating various ideas to accelerate different kernels and applying optimization techniques. Even in the final project, optimizing the matrix multiplication (matmul) kernel was the crucial part where I put most of my time and endeavors.
In this article, I aim to summarize optimization techniques applied to CUDA implementation step-by-step, starting from a naive approach. By incrementally applying each optimization, I will document how much each technique improves performance. Note that the performance measurements were all conducted with $A\in \mathbb{R}^{M\times K}, B \in \mathbb{R}^{K \times N}, C \in \mathbb{R}^{M\times N}, M=N=K=4096$ on an NVIDIA GeForce RTX 3060. All codes can be found at https://github.com/vantaa89/cuda-matmul/tree/master.
Kernel 0: Naive Matrix Multiplication
__global__ void matmul_kernel_naive(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x + blockDim.x * blockIdx.x;
int col = threadIdx.y + blockDim.y * blockIdx.y;
float acc = 0;
for(int k = 0; k < K; ++k){
acc += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = acc;
}
// Host code for launch
dim3 blockDim(32, 32);
dim3 gridDim((M+31)/32, (N+31)/32);
matmul_kernel_naive<<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);

This is the most basic matrix multiplication kernel. It uses a grid with M rows and N columns, where the $(i, j)$-th thread calculates $C_{ij}$. However, it doesn't use shared memory, repeatedly fetching matrices A and B directly from global memory. The memory access pattern has not been optimized yet. A throughput of 103 GFLOPS was measured.
Kernel 1: Block Tiling
template <int BLOCK_SIZE>
__global__ void matmul_kernel_block_tiling(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x;
int col = threadIdx.y;
int global_row = BLOCK_SIZE * blockIdx.x + threadIdx.x;
int global_col = BLOCK_SIZE * blockIdx.y + threadIdx.y;
__shared__ float A_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float B_block[BLOCK_SIZE][BLOCK_SIZE];
float acc = 0.0f;
const int num_tiles = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;
for(int t = 0; t < num_tiles; ++t){
const int tiled_row = BLOCK_SIZE * t + row;
const int tiled_col = BLOCK_SIZE * t + col;
A_block[row][col] = A[global_row * K + tiled_col];
B_block[row][col] = B[tiled_row * N + global_col];
__syncthreads();
for(int k = 0; k < BLOCK_SIZE; ++k){
acc += A_block[row][k] * B_block[k][col];
}
__syncthreads();
}
C[global_row * N + global_col] = acc;
}
// Host code for launch
const int BLOCK_SIZE = 16;
blockDim = dim3(BLOCK_SIZE, BLOCK_SIZE);
gridDim = dim3((M+BLOCK_SIZE-1)/BLOCK_SIZE, (N+BLOCK_SIZE-1)/BLOCK_SIZE);
matmul_kernel_block_tiling<BLOCK_SIZE><<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
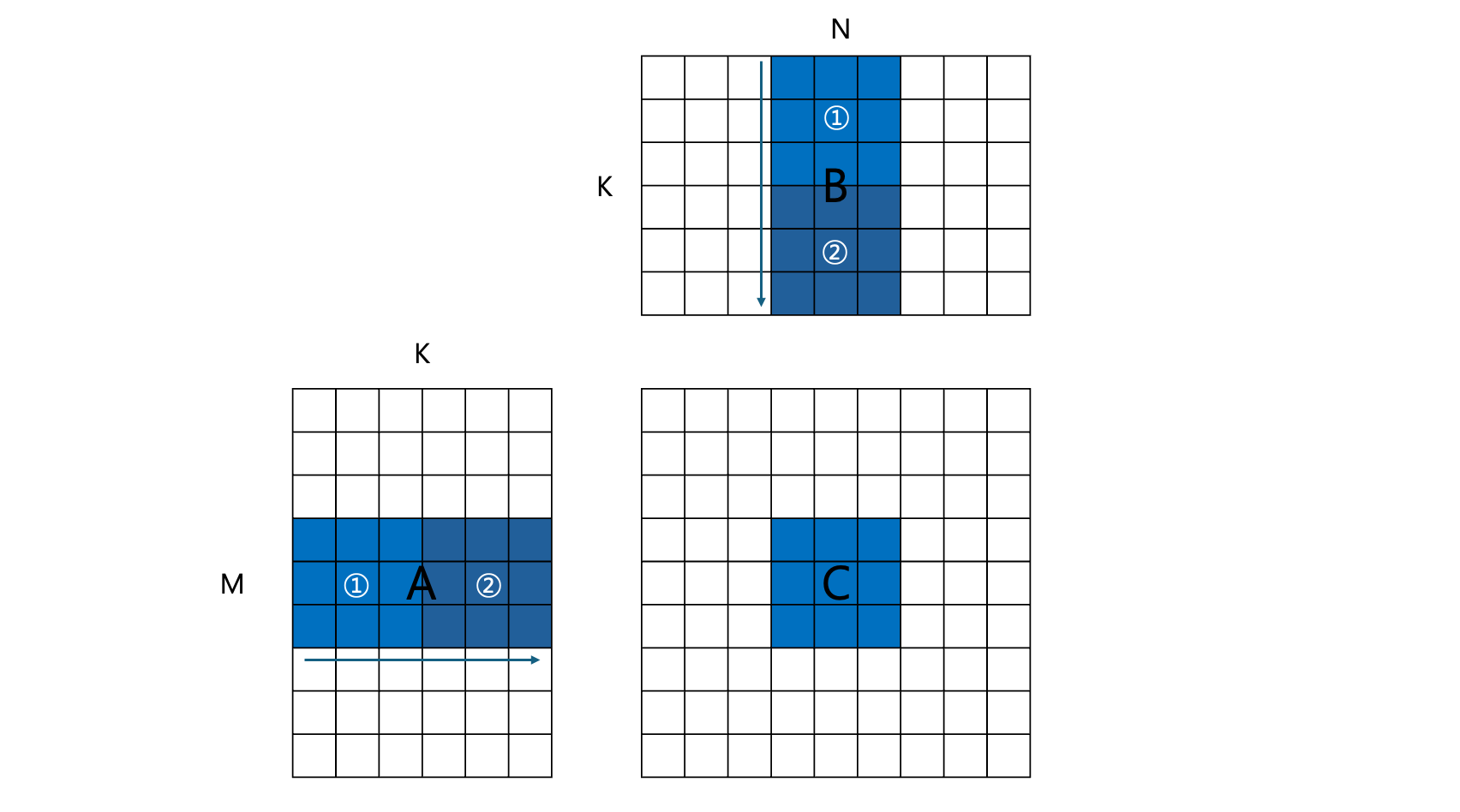
This is the kernel where a basic optimization called tiling is applied. In particular, the number of global memory accesses was significantly reduced by employing shared memory. Since each of the thread blocks processes a single tile of the resultant matrix $C$, this can be dubbed as block tiling. The figure above represents a thread block that computes the $3\times 3$ sub-matrix of $C$, colored in blue.
As demonstrated in the code, a thread block comprises BLOCK_SIZE * BLOCK_SIZE($16\times 16$) threads. In the figure, this is reduced to $3\times 3$ for convenience, meaning there are $3\times 3$ different threads in a thread block.
First, the thread block reads the elements of $A$ and $B$ belonging to ① from global memory, and copies them to A<mathsubscript>block and B<mathsubscript>block, which are stored in shared memory. Since there are $3\times 3$ elements to copy from each $A$ and $B$, and the thread block also comprises $3\times 3$ threads, each thread needs to read one element from $A$ and one from $B$.
After the elements are copied to shared memory, the computation is performed for these elements and the results are accumulated to the buffer acc of each thread. The same process is repeated for each ②, ③, and so on, by the for-loop over t. Here, __syncthreads() is employed to guarantee that the computation is held after the loading to shared memory is done. The throughput was measured to be 411 GFLOPS.
Kernel 2: Thread Tiling
template <int BLOCK_SIZE, int THREAD_TILE_SIZE>
__global__ void matmul_kernel_thread_tiling(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x * THREAD_TILE_SIZE;
int col = threadIdx.y;
int global_row = BLOCK_SIZE * blockIdx.x + row;
int global_col = BLOCK_SIZE * blockIdx.y + col;
__shared__ float A_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float B_block[BLOCK_SIZE][BLOCK_SIZE];
float acc[THREAD_TILE_SIZE];
for (int wm=0; wm<THREAD_TILE_SIZE; wm++) {
acc[wm] = 0.0f;
}
const int num_tiles = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;
for(int t = 0; t < num_tiles; ++t){
const int tiled_row = BLOCK_SIZE * t + row;
const int tiled_col = BLOCK_SIZE * t + col;
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
A_block[row+w1][col] = A[(global_row+w1) * K + tiled_col];
B_block[row+w1][col] = B[(tiled_row+w1) * N + global_col];
}
__syncthreads();
for(int k = 0; k < BLOCK_SIZE; ++k){
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
acc[w1] += A_block[row+w1][k] * B_block[k][col];
}
}
__syncthreads();
}
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
C[(global_row+w1) * N + global_col] = acc[w1];
}
}
// Host code for launch
const int BLOCK_SIZE = 32, THREAD_TILE_SIZE = 8;
blockDim = dim3(BLOCK_SIZE/THREAD_TILE_SIZE, BLOCK_SIZE);
gridDim = dim3((M+BLOCK_SIZE-1)/BLOCK_SIZE, (N+BLOCK_SIZE-1)/BLOCK_SIZE);
matmul_kernel_thread_tiling<BLOCK_SIZE, THREAD_TILE_SIZE><<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
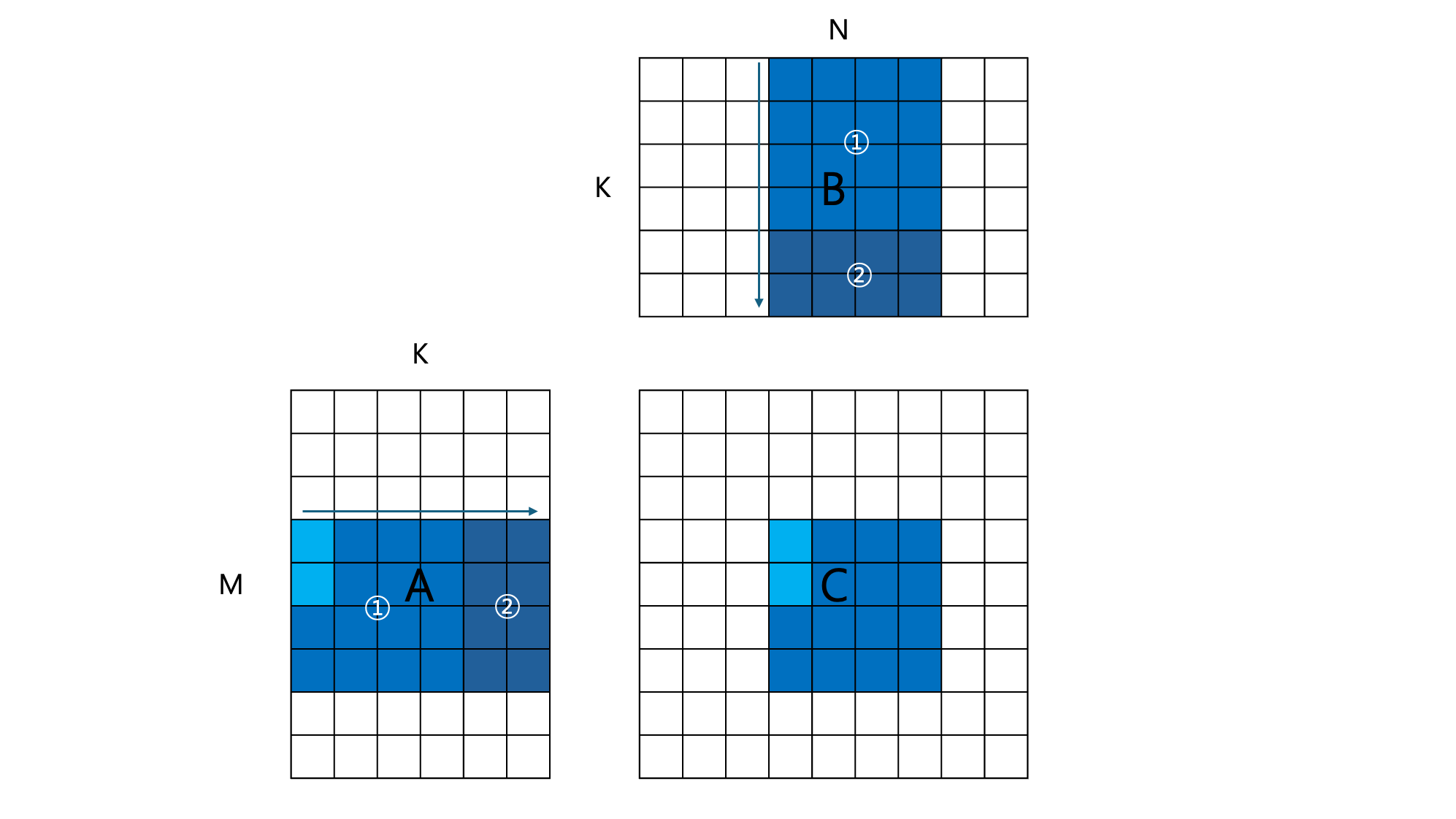
This is very similar to kernel 1, where block tiling is applied. However, while a thread in kernel 1 calculates a single resultant element of $C$, each thread in kernel 2 computes THREAD_TILE_SIZE adjacent elements in the row direction of C. This increases the workload per thread, effectively reducing the overhead which are irrelevant to actual computation.
The figure above shows an example for BLOCK_SIZE=4, THREAD_TILE_SIZE=2. The currently executed thread block is computing the $4\times 4$ sub-matrix of $C$, colored blue. However, since two elements are computed per thread, the thread block size becomes (4, 2), not (4, 4).
One can notice that acc has changed into an array, as opposed to a scalar in the original code. This is because each thread needs multiple accumulators corresponding to each elements of $C$ it is in charge of. Also, since the number of threads within a thread block no longer matches the number of elements in $A$ and $B$ it accesses, we now need a for-loop to load input elements into shared memory (A_block and B_block).
As a result, throughput increases to 745 GFLOPS.
Kernel 3: 2D Thread Tiling
template <int BLOCK_SIZE, int THREAD_TILE_SIZE>
__global__ void matmul_kernel_2d_thread_tiling(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x * THREAD_TILE_SIZE;
int col = threadIdx.y * THREAD_TILE_SIZE;
int global_row = BLOCK_SIZE * blockIdx.x + row;
int global_col = BLOCK_SIZE * blockIdx.y + col;
__shared__ float A_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float B_block[BLOCK_SIZE][BLOCK_SIZE];
float acc[THREAD_TILE_SIZE][THREAD_TILE_SIZE];
for (int wm=0; wm<THREAD_TILE_SIZE; wm++) {
for (int wn=0; wn<THREAD_TILE_SIZE; wn++) {
acc[wm][wn] = 0.0f;
}
}
const int num_tiles = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;
for(int t = 0; t < num_tiles; ++t){
const int tiled_row = BLOCK_SIZE * t + row;
const int tiled_col = BLOCK_SIZE * t + col;
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
for(int w2 = 0; w2 < THREAD_TILE_SIZE; w2++){
A_block[row+w1][col+w2] = A[(global_row+w1) * K + tiled_col + w2];
B_block[row+w1][col+w2] = B[(tiled_row+w1) * N + global_col + w2];
}
}
__syncthreads();
for(int k = 0; k < BLOCK_SIZE; ++k){
for(int w2 = 0; w2 < THREAD_TILE_SIZE; w2++){
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
acc[w1][w2] += A_block[row+w1][k] * B_block[k][col+w2];
}
}
}
__syncthreads();
}
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
for(int w2 = 0; w2 < THREAD_TILE_SIZE; w2++){
if(global_col+w2 < N && global_row + w1 < M)
C[(global_row+w1) * N + global_col+w2] = acc[w1][w2];
}
}
}
// Host code for launch
const int BLOCK_SIZE = 64, THREAD_TILE_SIZE = 8;
blockDim = dim3(BLOCK_SIZE/THREAD_TILE_SIZE, BLOCK_SIZE/THREAD_TILE_SIZE);
gridDim = dim3((M+BLOCK_SIZE-1)/BLOCK_SIZE, (N+BLOCK_SIZE-1)/BLOCK_SIZE);
matmul_kernel_2d_thread_tiling<BLOCK_SIZE, THREAD_TILE_SIZE><<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
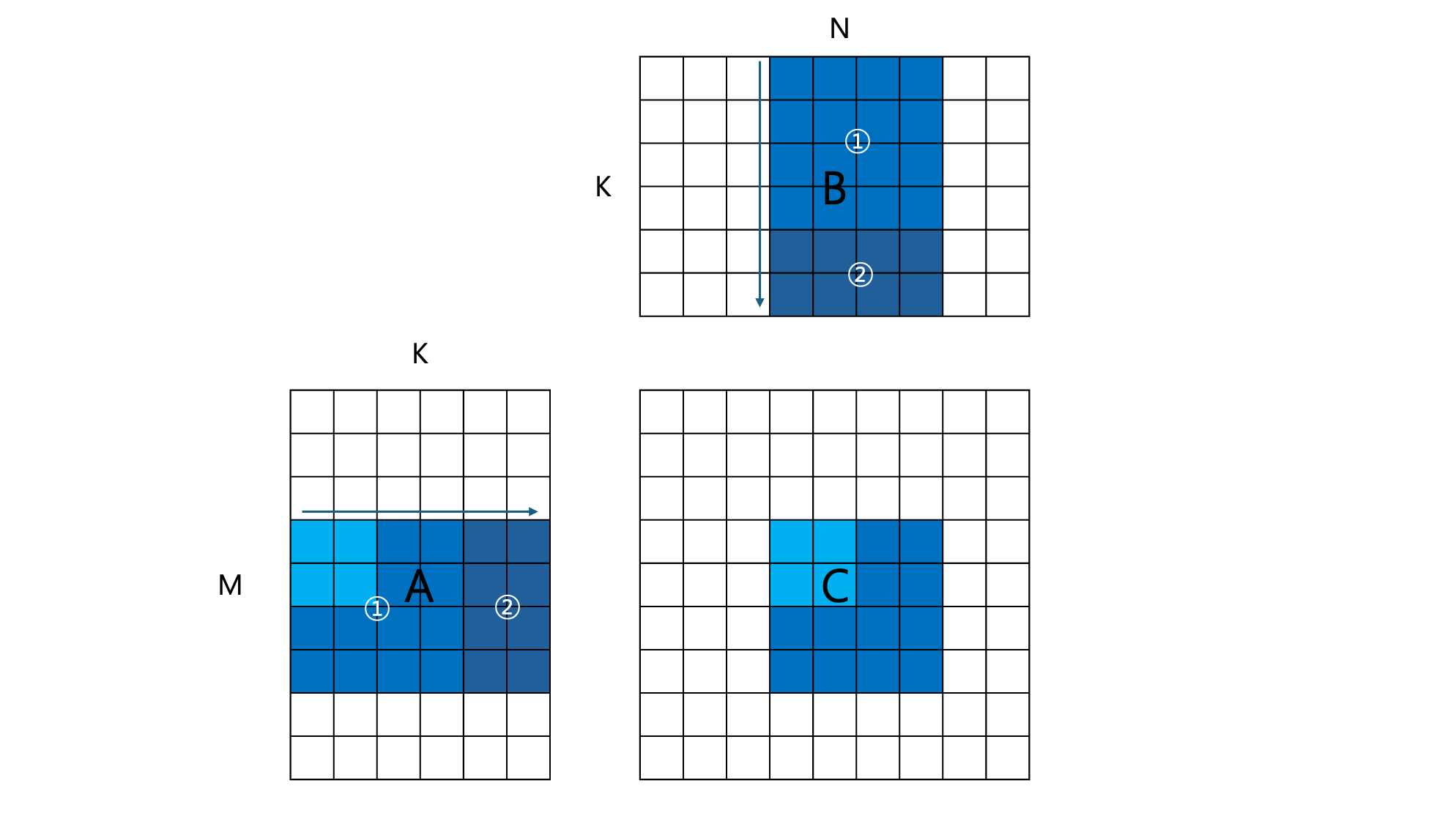
In the previous kernel 2, we improved the performance by increasing the number of elements in $C$ each thread computes. To further optimize the kernel, we can apply such thread tiling in a two-dimensional way. As depicted in the figure above, each thread block computes a sub-matrix of $C$, the resultant matrix, not a single row as it did in kernel 2. This further improved the throughput to 2150 GFLOPS!
Kernel 4: Tensor Core
#define WMMA_SIZE 16
__global__ void matmul_tc(half *A, half *B, float *C, int M, int N, int K){
int global_row = blockIdx.x * WMMA_SIZE;
int global_col = blockIdx.y * WMMA_SIZE;
wmma::fragment<wmma::matrix_a, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, float> c_frag;
wmma::fill_fragment(c_frag, 0.0f);
const int num_tiles = (K + WMMA_SIZE - 1) / WMMA_SIZE;
for(int t = 0; t < num_tiles; ++t){
int tiled_col = t * WMMA_SIZE, tiled_row = t * WMMA_SIZE;
wmma::load_matrix_sync(a_frag, &A[global_row * K + tiled_col], K);
wmma::load_matrix_sync(b_frag, &B[tiled_row * N + global_col], N);
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
}
wmma::store_matrix_sync(&C[global_row * N + global_col], c_frag, N, wmma::mem_row_major);
}
// Host code for launch
blockDim = dim3(32, 1);
gridDim = dim3((N+WMMA_SIZE-1)/WMMA_SIZE, (M+WMMA_SIZE-1)/WMMA_SIZE);
matmul_tc<<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
Now tensor cores come into play. Kernel 4 and 5 uses tensor cores to perform matrix multiplication for half-precision (FP16) inputs. Tensor cores are specialized computational units that exist separately from CUDA cores in each streaming multiprocessor of the GPU, allowing threads within a warp to cooperatively perform fast multiplication between two $16\times 16$ matrices. However, tensor cores only accept inputs with reduced precisions, such as FP16, BF16, or even sub-8 bit data types. The output (matrix C) can be chosen as full-precision, but some loss of precision must be considered.
I used a library called WMMA(Warp Matrix Multiply-Accumulate) to utilize tensor core, partly because CUTLASS was not allowed for the project. The basic principles are similar to block tiling (kernel 1), but blockDim must be set to (32, 1) so that a thread block fits exactly in a single warp. Thus, a thread block(=warp) processes a $16\times 16$ submatrix of the resultant matrix $C$.
WMMA operates by performing multiplication between wmma::matrix_a (left matrix) and wmma::matrix_b (right matrix) and accumulating the result in wmma::accumulator. Therefore, wmma::fragment was employed to define the input and output matrices recognized by the tensor core. The buffers defined so are actually distributed and stored in each thread's registers. Then, similar to kernel 1, tiles are slid while accumulating the resultant submatrix. wmma::load_matrix_sync loads 16\times 16 data from global memory into wmma::fragment, wmma::mma_sync performs the actual matrix multiply-accumulate on the loaded values, and wmma::store_matrix_sync writes the data in c_frag to the global memory location. Using tensor cores, the throughput increased to 3066 GFLOPS.
Kernel 5: Tensor Core + Warp Tiling
template<int WARP_TILE_SIZE1, int WARP_TILE_SIZE2>
__global__ void matmul_tc_2d_warp_tiling(half *A, half *B, float *C, int M, int N, int K) {
int global_row = blockIdx.x * WMMA_SIZE * WARP_TILE_SIZE1; // 0 ~ M
int global_col = blockIdx.y * WMMA_SIZE * WARP_TILE_SIZE2; // 0 ~ N
wmma::fragment<wmma::matrix_a, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> b_frag[WARP_TILE_SIZE2];
wmma::fragment<wmma::accumulator, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, float> c_frag[WARP_TILE_SIZE1][WARP_TILE_SIZE2];
for(int i = 0; i < WARP_TILE_SIZE1; i++){
for(int j = 0; j < WARP_TILE_SIZE2; j++)
wmma::fill_fragment(c_frag[i][j], 0.0f);
}
const int num_tiles = (K + WMMA_SIZE - 1) / WMMA_SIZE;
for(int t = 0; t < num_tiles; ++t){
int tiled_col = t * WMMA_SIZE, tiled_row = t * WMMA_SIZE;
for(int j = 0; j < WARP_TILE_SIZE2; j++)
wmma::load_matrix_sync(b_frag[j], &B[tiled_row * N + global_col + j * WMMA_SIZE], N);
for(int i = 0; i < WARP_TILE_SIZE1; i++){
wmma::load_matrix_sync(a_frag, &A[(global_row + i * WMMA_SIZE) * K + tiled_col], K);
for(int j = 0; j < WARP_TILE_SIZE2; j++){
wmma::mma_sync(c_frag[i][j], a_frag, b_frag[j], c_frag[i][j]);
}
}
}
for(int i = 0; i < WARP_TILE_SIZE1; i++){
for(int j = 0; j < WARP_TILE_SIZE2; j++){
wmma::store_matrix_sync(&C[(global_row + i * WMMA_SIZE) * N + global_col + j * WMMA_SIZE], c_frag[i][j], N, wmma::mem_row_major);
}
}
}
// Host code for launch
const int WARP_TILE_SIZE1 = 4, WARP_TILE_SIZE2 = 4;
blockDim = dim3(32, 1);
gridDim = dim3((N+WMMA_SIZE-1)/WMMA_SIZE/WARP_TILE_SIZE1, (M+WMMA_SIZE-1)/WMMA_SIZE/WARP_TILE_SIZE2);
matmul_tc_2d_warp_tiling<WARP_TILE_SIZE1, WARP_TILE_SIZE2><<<gridDim
Considering the powerful performance of tensor cores, the throughput increase in kernel 4 does not seem to be significant. Particularly, considering that we have sacrificed precision, a 1.5x improvement is not very satisfactory. This can be attributed to significant overhead caused in areas other than actual WMMA computation.
Therefore, applying 2D tiling similar to what was used in kernel 3 can increase the workload per warp, thereby effectively reducing the non-computational overhead. With this applied, each thread block computes a larger sub-matrix than the previous $16\times 16$. In the code, this was achieved by defining an array of wmma::fragment's and performing multiple computations per single load. Applying this optimization resulted in a final throughput increased to 6688 GFLOPS.
Conclusion
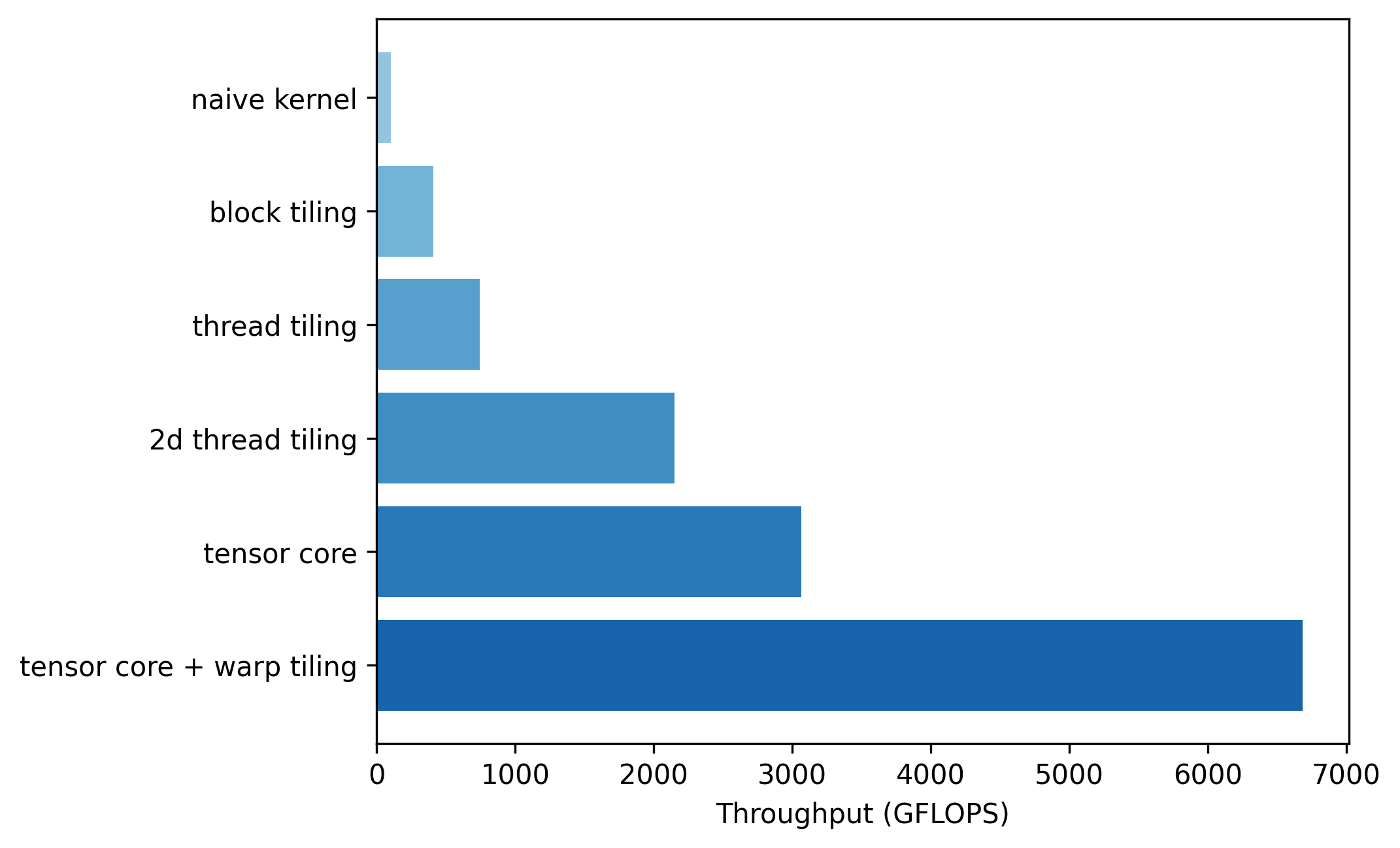
While the naive kernel 0 achieved only 103 GFLOPS, kernel 5 where tensor cores and warp tiling were applied achieved 6688 GFLOPS, showing a 65-fold speedup. Even kernel 3, which didn't sacrifice precision at all, achieved a 21-fold speedup compared to kernel 0, demonstrating how important kernel optimizations are. I also note that I have considered many factors including but not limited to number of global memory I/O accesses, coalesced memory access, and shared memory bank conflicts, while implementing each kernel.
The codes above don't implement boundary checks, so depending on the kernel, they generally produce correct results only when matrix sizes are multiples of 32. Boundary checks can be implemented by writing 0 for out-of-bounds cases when loading values to shared memory, or by using zero padding methods.
References
- Otomo Hiroyuki, "Tensorコアを使ってみた," Fixstars Tech Blog
- "OpenCL matrix-multiplication SGEMM tutorial"
- Lei Mao, "CUDA Matrix Multiplication Optimization"
- Jeremy Appleyard and Scott Yokim, "Programming Tensor Cores in CUDA 9," NVIDIA Technical Blog
- Andrew Kerr, Duane Merrill, Julien Demouth and John Tran, "CUTLASS: Fast Linear Algebra in CUDA C++," NVIDIA Technical Blog
필자는 이번 학기 확장형 고성능 컴퓨팅 수업을 들으면서, pthread, OpenMP, OpenCL, CUDA 등 다양한 라이브러리와 API를 활용해 행렬 곱셈을 최적화하는 과제를 수행했다. 특히 학기말 프로젝트에서는 GPU를 활용해 딥러닝 모델의 연산을 가속화하면서 수업에서 다루지 않았던 tensor core또한 사용해볼 수 있었고, 행렬 곱셈 kernel을 최적화하기 위한 다양한 아이디어를 고민하고 최적화 기법들을 적용해보는 값진 경험을 얻을 수 있었다.
이 글에서는 CUDA를 이용해 naive한 구현에서부터 단계별로 최적화를 적용해보면서, 각각의 최적화가 성능을 얼마나 향상시키는지를 정리해보려고 한다. 성능 측정은 모두 $A\in \mathbb{R}^{M\times K}, B \in \mathbb{R}^{K \times N}, C \in \mathbb{R}^{M\times N}, M=N=K=4096$로 설정한 후 NVIDIA GeForce RTX 3060에서 측정하였다. 모든 코드는 https://github.com/vantaa89/cuda-matmul/tree/master에서 확인할 수 있다.
Kernel 0: Naive Matrix Multiplication
__global__ void matmul_kernel_naive(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x + blockDim.x * blockIdx.x;
int col = threadIdx.y + blockDim.y * blockIdx.y;
float acc = 0;
for(int k = 0; k < K; ++k){
acc += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = acc;
}
// Host code for launch
dim3 blockDim(32, 32);
dim3 gridDim((M+31)/32, (N+31)/32);
matmul_kernel_naive<<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
가장 기본적인 행렬 곱셈 커널이다. M개의 row, N개의 column으로 이루어진 grid를 사용하여, $(i, j)$번 thread가 $C_{ij}$를 계산하는 식으로 병렬화가 이루어져 있다. 다만 Shared memory를 사용하지 않아 A와 B 행렬을 매번 global memory에서 직접 가져오고 있으며, 메모리 접근 패턴 또한 최적화되어 있지 않은 모습이다. 103 GFLOPS의 throughput이 측정되었다.
Kernel 1: Block Tiling
template <int BLOCK_SIZE>
__global__ void matmul_kernel_block_tiling(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x;
int col = threadIdx.y;
int global_row = BLOCK_SIZE * blockIdx.x + threadIdx.x;
int global_col = BLOCK_SIZE * blockIdx.y + threadIdx.y;
__shared__ float A_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float B_block[BLOCK_SIZE][BLOCK_SIZE];
float acc = 0.0f;
const int num_tiles = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;
for(int t = 0; t < num_tiles; ++t){
const int tiled_row = BLOCK_SIZE * t + row;
const int tiled_col = BLOCK_SIZE * t + col;
A_block[row][col] = A[global_row * K + tiled_col];
B_block[row][col] = B[tiled_row * N + global_col];
__syncthreads();
for(int k = 0; k < BLOCK_SIZE; ++k){
acc += A_block[row][k] * B_block[k][col];
}
__syncthreads();
}
C[global_row * N + global_col] = acc;
}
// Host code for launch
const int BLOCK_SIZE = 16;
blockDim = dim3(BLOCK_SIZE, BLOCK_SIZE);
gridDim = dim3((M+BLOCK_SIZE-1)/BLOCK_SIZE, (N+BLOCK_SIZE-1)/BLOCK_SIZE);
matmul_kernel_block_tiling<BLOCK_SIZE><<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
Tiling이라 불리는 기본적인 최적화를 적용한 kernel이다. 특히 shared memory를 사용해 global memory로의 접근 횟수를 크게 줄였다. 각각의 block이 결과행렬 C의 하나의 tile을 처리하는 방식이므로 block tiling이라 이름붙일 수 있다. 위 그림은 푸른 색으로 색칠된 C의 $3\times 3$ submatrix를 계산하는 thread block을 표현한 것이다.
코드를 보면 하나의 thread block은 BLOCK_SIZE * BLOCK_SIZE($16\times 16$) 개의 thread로 구성되어 있다. 그림에서는 편의상 이를 $3\times 3$로 줄여 표현하였다. 이 경우 하나의 thread block에는 $3\times 3$개의 thread가 들어있는 식이 된다.
먼저 thread block이 ①에 속하는 A와 B의 element들을 global memory에서 읽어 shared memory인 A_block과 B_block으로 복사한다. 이때 복사의 대상이 되는 element의 개수가 (A, B에서 각각) $3\times 3$개이고, thread block도 $3\times 3$이므로 한 thread가 A, B에서 각각 하나씩의 원소를 읽어오면 된다. Shared memory로의 복사가 끝난 후에는 현재 shared memory에 올라와 있는 element들을 사용해서 계산을 수행하고, 각 thread의 acc에 누산(accumulate)한다. 같은 과정을 ②, ③, ...에 대해서 반복하면 된다(t에 대한 for문).
이때, shared memory로의 loading이 완전히 완료된 후에 계산이 수행됨을 보장하기 위해 __syncthreads()를 사용한다. Throughput은 411 GFLOPS로 측정되었다.
Kernel 2: Thread Tiling
template <int BLOCK_SIZE, int THREAD_TILE_SIZE>
__global__ void matmul_kernel_thread_tiling(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x * THREAD_TILE_SIZE;
int col = threadIdx.y;
int global_row = BLOCK_SIZE * blockIdx.x + row;
int global_col = BLOCK_SIZE * blockIdx.y + col;
__shared__ float A_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float B_block[BLOCK_SIZE][BLOCK_SIZE];
float acc[THREAD_TILE_SIZE];
for (int wm=0; wm<THREAD_TILE_SIZE; wm++) {
acc[wm] = 0.0f;
}
const int num_tiles = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;
for(int t = 0; t < num_tiles; ++t){
const int tiled_row = BLOCK_SIZE * t + row;
const int tiled_col = BLOCK_SIZE * t + col;
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
A_block[row+w1][col] = A[(global_row+w1) * K + tiled_col];
B_block[row+w1][col] = B[(tiled_row+w1) * N + global_col];
}
__syncthreads();
for(int k = 0; k < BLOCK_SIZE; ++k){
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
acc[w1] += A_block[row+w1][k] * B_block[k][col];
}
}
__syncthreads();
}
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
C[(global_row+w1) * N + global_col] = acc[w1];
}
}
// Host code for launch
const int BLOCK_SIZE = 32, THREAD_TILE_SIZE = 8;
blockDim = dim3(BLOCK_SIZE/THREAD_TILE_SIZE, BLOCK_SIZE);
gridDim = dim3((M+BLOCK_SIZE-1)/BLOCK_SIZE, (N+BLOCK_SIZE-1)/BLOCK_SIZE);
matmul_kernel_thread_tiling<BLOCK_SIZE, THREAD_TILE_SIZE><<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
Block tiling이 적용된 kernel 1과 거의 비슷한 방식이다. 다만 kernel 1에서는 한 thread가 결과 행렬 C의 한 원소를 계산했던 데 비해 kernel 2는 **한 thread가 C의 row방향으로 인접한 THREAD_TILE_SIZE개 원소를 계산한다. 이는 thread 당 작업의 양(workload per thread)를 높여, 실제 계산과 무관한 overhead의 비중을 감소시키는 효과를 준다.
위 그림은 BLOCK_SIZE=4, THREAD_TILE_SIZE=2인 예시이다. 현재 실행되는 thread block은 결과 행렬 C에서 색칠되어 있는 $4\times 4$ 부분행렬을 계산하려 하고 있다. 다만 한 thread가 C에서 2개씩의 원소(하늘색)를 계산하므로 thread block의 size는 (4, 4)가 아닌 (4, 2)가 된다.
코드를 살펴보면 먼저 acc가 배열로 바뀐 것을 확인할 수 있다. 기존에 각 thread가 C의 원소 한 개 씩을 계산하던 데 비해, kernel 2는 여러 원소를 계산하므로 accumulator가 여러 개 필요한 것이다. 또한 thread block 내 thread의 개수와 해당 block이 접근하는 A, B 행렬의 원소 개수가 일치하지 않게 되면서 shared memory(A_block와 B_block)로 데이터를 로드해 오는 코드에 반복문이 필요해지는 것을 확인할 수 있다.
이와 같이 thread tiling을 적용한 결과 throughput은 745 GFLOPS로 증가하였다.
Kernel 3: 2D Thread Tiling
template <int BLOCK_SIZE, int THREAD_TILE_SIZE>
__global__ void matmul_kernel_2d_thread_tiling(float *A, float *B, float *C, int M, int N, int K) {
int row = threadIdx.x * THREAD_TILE_SIZE;
int col = threadIdx.y * THREAD_TILE_SIZE;
int global_row = BLOCK_SIZE * blockIdx.x + row;
int global_col = BLOCK_SIZE * blockIdx.y + col;
__shared__ float A_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float B_block[BLOCK_SIZE][BLOCK_SIZE];
float acc[THREAD_TILE_SIZE][THREAD_TILE_SIZE];
for (int wm=0; wm<THREAD_TILE_SIZE; wm++) {
for (int wn=0; wn<THREAD_TILE_SIZE; wn++) {
acc[wm][wn] = 0.0f;
}
}
const int num_tiles = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;
for(int t = 0; t < num_tiles; ++t){
const int tiled_row = BLOCK_SIZE * t + row;
const int tiled_col = BLOCK_SIZE * t + col;
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
for(int w2 = 0; w2 < THREAD_TILE_SIZE; w2++){
A_block[row+w1][col+w2] = A[(global_row+w1) * K + tiled_col + w2];
B_block[row+w1][col+w2] = B[(tiled_row+w1) * N + global_col + w2];
}
}
__syncthreads();
for(int k = 0; k < BLOCK_SIZE; ++k){
for(int w2 = 0; w2 < THREAD_TILE_SIZE; w2++){
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
acc[w1][w2] += A_block[row+w1][k] * B_block[k][col+w2];
}
}
}
__syncthreads();
}
for(int w1 = 0; w1 < THREAD_TILE_SIZE; w1++){
for(int w2 = 0; w2 < THREAD_TILE_SIZE; w2++){
if(global_col+w2 < N && global_row + w1 < M)
C[(global_row+w1) * N + global_col+w2] = acc[w1][w2];
}
}
}
// Host code for launch
const int BLOCK_SIZE = 64, THREAD_TILE_SIZE = 8;
blockDim = dim3(BLOCK_SIZE/THREAD_TILE_SIZE, BLOCK_SIZE/THREAD_TILE_SIZE);
gridDim = dim3((M+BLOCK_SIZE-1)/BLOCK_SIZE, (N+BLOCK_SIZE-1)/BLOCK_SIZE);
matmul_kernel_2d_thread_tiling<BLOCK_SIZE, THREAD_TILE_SIZE><<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
바로 전의 kernel 2에서는 thread당 계산하는 C의 원소 수를 늘림으로써 성능을 증가시켰다. 이때, 하나의 thread가 인접한 row의 원소들을 몇 개씩 묶어 같이 계산하는 방식을 사용하였다. 이를 더욱 개선하면 위 그림과 같이 thread tiling을 2D로 적용할 수도 있다. 위 그림의 경우, 한 thread block은 C의 $4\times 4$ submatrix를 맡아 계산하도록 되어 있다. 하지만 thread block 내 각 thread가 $2\times2$개씩의 원소를 계산하므로(하늘색) blockDim은 $4\times 4$가 아닌 $2\times 2$가 된다. 이를 적용하였을 때 throughput은 2150 GFLOPS로 증가하였다.
Kernel 4: Tensor Core
#define WMMA_SIZE 16
__global__ void matmul_tc(half *A, half *B, float *C, int M, int N, int K){
int global_row = blockIdx.x * WMMA_SIZE;
int global_col = blockIdx.y * WMMA_SIZE;
wmma::fragment<wmma::matrix_a, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, float> c_frag;
wmma::fill_fragment(c_frag, 0.0f);
const int num_tiles = (K + WMMA_SIZE - 1) / WMMA_SIZE;
for(int t = 0; t < num_tiles; ++t){
int tiled_col = t * WMMA_SIZE, tiled_row = t * WMMA_SIZE;
wmma::load_matrix_sync(a_frag, &A[global_row * K + tiled_col], K);
wmma::load_matrix_sync(b_frag, &B[tiled_row * N + global_col], N);
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
}
wmma::store_matrix_sync(&C[global_row * N + global_col], c_frag, N, wmma::mem_row_major);
}
// Host code for launch
blockDim = dim3(32, 1);
gridDim = dim3((N+WMMA_SIZE-1)/WMMA_SIZE, (M+WMMA_SIZE-1)/WMMA_SIZE);
matmul_tc<<<gridDim, blockDim>>>(a_d, b_d, c_d, M, N, K);
Kernel 4와 5의 경우 tensor core를 사용하여 입력 행렬 A와 B 행렬이 half-precision(16 bit)인 경우에 대해 곱셈을 수행한다. Tensor core란 GPU 내 각 streaming multiprocessor에 cuda core 외에 별도로 존재하는 계산 장치로, warp 내의 thread들이 협력하여 두 $16\times 16$ 행렬간의 곱셈을 빠르게 수행할 수 있다. 다만 Tensor core는 full-precision(float)이 아닌, half-precision(half)만을 입력으로 받는다. 출력(C 행렬)은 full-precision으로 선택할 수 있으나, 어느 정도 정밀도가 떨어지는 것은 감안해야 한다.
CUDA에서 tensor core를 사용하기 위한 라이브러리는 WMMA(Warp Matrix Multiply-Accumulate)이다. 위 코드에서는 WMMA를 이용해 행렬 곱셈을 수행하도록 하였다. 기본적인 원리는 block tiling(kernel 1)과 유사하지만, 한 thread block이 반드시 한 warp가 되도록 blockDim을 (32, 1)로 설정해주어야 한다. 즉 하나의 thread block=warp가 결과 행렬 C의 $16\times 16$ submatrix를 맡아 계산하게 된다.
WMMA는 wmma::matrix_a를 왼쪽 행렬, wmma::matrix_b를 오른쪽 행렬로 하여 둘 사이의 곱셈을 수행해 wmma::accumulator에 그 결과를 누산(accumulate)시키는 식으로 작동한다. 따라서 먼저 wmma::fragment를 사용해 tensor core에 넣어줄 입력행렬과 출력행렬을 정의해주었다. 이때 wmma::fragment로 정의된 버퍼는 실제로는 각 thread의 레지스터에 나뉘어 저장된다. 그 다음으로는 kernel 1에서와 비슷한 방식으로 tile을 움직이며 결과를 누산한다. wmma::load_matrix_sync는 해당 global memory에 있는 데이터를 $16\times 16$개씩 wmma::fragment로 불러오는 역할을 하며, wmma::mma_sync는 불러온 값을 토대로 실제 matrix multiply-accumulate를 수행하는 부분이다. wmma::store_matrix_sync를 수행시키면 c_frag에 있던 데이터를 global memory에 써주게 된다. Tensor core를 사용한 결과 throughput은 3066 GFLOPS까지 증가하였다.
Kernel 5: Tensor Core + Warp Tiling
template<int WARP_TILE_SIZE1, int WARP_TILE_SIZE2>
__global__ void matmul_tc_2d_warp_tiling(half *A, half *B, float *C, int M, int N, int K) {
int global_row = blockIdx.x * WMMA_SIZE * WARP_TILE_SIZE1; // 0 ~ M
int global_col = blockIdx.y * WMMA_SIZE * WARP_TILE_SIZE2; // 0 ~ N
wmma::fragment<wmma::matrix_a, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, half, wmma::row_major> b_frag[WARP_TILE_SIZE2];
wmma::fragment<wmma::accumulator, WMMA_SIZE, WMMA_SIZE, WMMA_SIZE, float> c_frag[WARP_TILE_SIZE1][WARP_TILE_SIZE2];
for(int i = 0; i < WARP_TILE_SIZE1; i++){
for(int j = 0; j < WARP_TILE_SIZE2; j++)
wmma::fill_fragment(c_frag[i][j], 0.0f);
}
const int num_tiles = (K + WMMA_SIZE - 1) / WMMA_SIZE;
for(int t = 0; t < num_tiles; ++t){
int tiled_col = t * WMMA_SIZE, tiled_row = t * WMMA_SIZE;
for(int j = 0; j < WARP_TILE_SIZE2; j++)
wmma::load_matrix_sync(b_frag[j], &B[tiled_row * N + global_col + j * WMMA_SIZE], N);
for(int i = 0; i < WARP_TILE_SIZE1; i++){
wmma::load_matrix_sync(a_frag, &A[(global_row + i * WMMA_SIZE) * K + tiled_col], K);
for(int j = 0; j < WARP_TILE_SIZE2; j++){
wmma::mma_sync(c_frag[i][j], a_frag, b_frag[j], c_frag[i][j]);
}
}
}
for(int i = 0; i < WARP_TILE_SIZE1; i++){
for(int j = 0; j < WARP_TILE_SIZE2; j++){
wmma::store_matrix_sync(&C[(global_row + i * WMMA_SIZE) * N + global_col + j * WMMA_SIZE], c_frag[i][j], N, wmma::mem_row_major);
}
}
}
// Host code for launch
const int WARP_TILE_SIZE1 = 4, WARP_TILE_SIZE2 = 4;
blockDim = dim3(32, 1);
gridDim = dim3((N+WMMA_SIZE-1)/WMMA_SIZE/WARP_TILE_SIZE1, (M+WMMA_SIZE-1)/WMMA_SIZE/WARP_TILE_SIZE2);
matmul_tc_2d_warp_tiling<WARP_TILE_SIZE1, WARP_TILE_SIZE2><<<gridDim
위의 kernel 4는 tensor core의 막강한 성능을 고려했을 때 throughput을 크게 증가시키지는 못하고 있다. 특히 precision을 희생한 것을 생각하면, 약 1.5배의 성능 향상은 매우 만족스럽지 못한 결과이다. 이는 실제 WMMA 계산 외 다른 곳에서 overhead가 크게 작용한 것이 원인이라고 생각할 수 있다.
따라서 여기에 kernel 3에서 사용한 것과 같은 2D tiling을 적용하면 각 warp 당 workload를 증가시킴으로써, 계산 이외의 overhead 비중을 줄일 수 있다. 이를 적용하면 각각의 thread block은 결과행렬에서 기존의 $16\times16$보다 큰 submatrix를 계산하게 된다. 코드에서는 이를 위해서 wmma::fragment들을 배열로 만들어주고, 한 번의 load로 계산을 여러 번 수행하는 것을 확인할 수 있다. 이와 같은 최적화를 수행한 결과 throughput은 최종적으로 6688 GFLOPS까지 증가하였다.
결론
Naive하게 구현한 kernel 0의 성능이 103 GFLOPS에 그쳤던 것에 비해 tensor core에 warp tiling까지 적용한 kernel 5는 6688 GFLOPS의 성능을 내, 65배에 달하는 speedup을 보여주었다. 심지어 precision을 희생하지 않은 kernel 3도 kernel 0에 비해서는 21배의 speedup을 달성하여, global memory I/O 횟수와 coalesced memory access, shared memory bank conflict 등을 고려한 최적화가 얼마나 큰 영향을 끼치는지 알 수 있었다.
위의 코드들에는 bound check가 구현되어 있지 않아, kernel에 따라 다르지만 대체로 행렬의 크기가 32의 배수일 때에만 올바른 결과를 낸다. Bound check의 경우 shared memory로 값을 불러올 때 out of bounds인 경우 0을 써주거나, zero padding을 하는 방식 등으로 구현이 가능하다.
참고문헌
- Otomo Hiroyuki, "Tensorコアを使ってみた," Fixstars Tech Blog
- "OpenCL matrix-multiplication SGEMM tutorial"
- Lei Mao, "CUDA Matrix Multiplication Optimization"
- Jeremy Appleyard and Scott Yokim, "Programming Tensor Cores in CUDA 9," NVIDIA Technical Blog
- Andrew Kerr, Duane Merrill, Julien Demouth and John Tran, "CUTLASS: Fast Linear Algebra in CUDA C++," NVIDIA Technical Blog