
컴퓨터를 켤 때부터 끌 때까지 PC가 $a_0, a_1, \cdots, a_{n-1}$의 sequence로 움직인다고 가정하자. 주소 $a_k$에 instruction $I_k$가 있는 식이다. 이때, PC가 $a_k$에서 $a_{k-1}$으로 옮겨가는 것을 control transfer라고 지칭하며, control transfer의 sequence인 ${\cdots, (a_{k-1}, a_k), (a_k, a_{k+1}), \cdots}$를 프로세서의 control flow라고 한다.
- smooth sequence, 즉 $I_k$와 $I_{k+1}$이 메모리 상에 나란히 위치해 있는 경우는 가장 간단한 control flow라고 할 수 있다.
- 이는
jmp, call, ret 등의 프로그램 내부 요인에 의해 갑작스럽게 변화가 생기기도 한다.
그런데, 프로그램 실행과 관련없는 시스템의 상태에 의해서도 smooth flow에 갑작스러운 변화가 생길 수 있다.
- 예시로 일정시간마다 꺼지는 timer를 처리하거나, 네트워크 패킷을 수신하고 저장하는 것, child process가 terminate되었을 때 parent에게 통보하는 것 등
이러한 것들은 Exceptional Control Flow(ECF)를 통해 처리되며, HW, OS, application 등 모든 레벨이 관여한다.
8.1. Exceptions
Exception은 OS와 HW가 각각 부분적으로 구현한다. 그 정의는 프로세서 상태의 변화에 대응하여 control flow에 일어나는 갑작스러운 변화라 할 수 있다.
- 이때 프로세서 상태의 변화는 event라 부르며, 프로세서 내의 bit 혹은 signal으로 인코딩된다
- event는
- ZeroDivion과 같이 현재의 instruction과 직접적 연관이 있을수도,
- system timer off나 I/O 요청의 완료와 같이 현재 다루는 instruction과 무관할 수도 있다
Exception Handling
Exception handling은 하드웨어와 소프트웨어의 복잡한 상호작용으로 구현된다.
- 각 exception에는 exception number라는 숫자가 부여되어 있다
- 이 중 몇 개(e.g. zero division error, memory violation)는 프로세서 디자이너가, 몇 개(e.g. system call)는 OS 디자이너가 부여한 숫자이다.
- 컴퓨터가 부팅될 때 OS는 exception table이라는 표를 만드는데, $k$번째 entry가 exception number $k$에 대한 handler를 가리키는 식이다.
- Exception의 발생은 procedure의 호출과도 유사하지만 몇 가지의 차이점이 있다.
- 스택에 저장하는 return address가 현재의 PC일수도, 다음 instruction의 PC일 수도 있음 (procedure의 경우 항상 다음 inst.의 PC)
- return address뿐만 아니라 condition code 등을 담고 있는
EFLAG 등의 프로세서 상태를 스택에 함께 푸쉬
- 유저 프로그램에서 커널로 컨트롤이 넘어갈 때에는 유저 스택이 아닌 커널 스택에 푸쉬
- exception handler는 kernel mode에서 동작하기 때문에 모든 시스템 자원에 접근이 가능하다.
- handler가 exception의 처리를 마친 후에는 return from interrupt instruction이 발동하여, 적절한 상태로 돌아가고 중단시킨 프로그램이 있을 경우 돌아간다.
Exception의 종류
Exception은 interrupt, trap, fault, abort의 네 가지로 분류된다.
- Interrupt: 프로세서 외부의 I/O 장치의 신호에 의해서 비동기적으로 일어남
- 비동기적(asynchronous)인 이유는 특정 instruction의 실행에 의한 결과가 아니기 때문이다. interrupt를 제외한 나머지 exception은 모두 특정 instruction에 의해 발생하므로 동기적(synchronous)이다.
- I/O 장치가 프로세서에 signal을 주고 시스템 버스로 exception number를 전달하면, 실행중이던 instruction까지만 실행한 후 interrupt handler가 컨트롤을 획득한다.
- handler가 종료되면 다음 instruction으로 돌아가, 마치 interrupt가 발생하지 않았던 것과 같은 결과가 나온다.
- Trap: instruction이 의도적으로 발생시킨 exception
- 가장 중요한 용도는 system call으로, 유저 프로그램과 커널 사이의 인터페이스를 마치 procedure와 유사한 형태로 제공해준다.
syscall n의 instruction을 실행함으로써 파일 읽기(read), 프로세스 생성(fork), 프로그램 로드(execve), exit과 같은 작업들이 가능하다.- system call은 커널 모드에서 작동하므로 일반 procedure와는 다르게 특수 instruction의 사용이 가능하고, 커널 스택에도 접근이 가능하다
- Fault: handler가 수정할 가능성이 있는 exception
- handler가 오류 정정에 성공할 시 faulting instruction으로 돌아가 이를 다시 실행한다.
- 정정이 불가능할 시 커널의 abort 루틴이 실행되어 프로그램이 종료된다.
- e. g. page fault: 메모리에 없는 가상 메모리 주소를 참조하여, 디스크로부터 복사해온 후 fetch해야 하는 경우. page fault handler가 메모리를 복사해온 후 instruction이 재실행
- Aborts: 복구가 불가능한 하드웨어 오류
- e.g. DRAM/SRAM의 parity 오류(memory corruption)
- 이 경우 애플리케이션으로 돌아가지 않고 abort 루틴으로 컨트롤이 넘어가고 애플리케이션이 종료됨
Linux/x86-64 시스템에서의 exception
- 256개의 exception이 존재: 0~31은 intel이 정의한 것이며 32~255는 OS가 정의한 것(즉 시스템마다 다를 수 있음)
- faults: Divide Error, General protection fault(segmentation fault, 주로 read-only section으로의 쓰기 시도나 가상메모리상의 정의되지 않은 영역에 접근 시도), page fault 등
- aborts: machine check(치명적인 HW 오류)
- system calls:
read, write, execve, kill 등이 존재
- system call은 exception number와는 별도로 syscall 번호와 jump table을 가짐
- 이를 사용해
syscall n으로 호출하는 것도 가능하지만 보통 wrapper 함수(system-level function이라 부름)를 활용
syscall instruction 실행시에는 %rax가 syscall number를, %rdi, %rsi, %r10, %r9, %r8 등이 1~6번째 argument를 전달하는 식. 반환값은 %rax에 덮어쓰기됨
8.2. Process
Exception은 OS의 커널이 프로세스(process)라는 개념을 제공할 수 있도록 하는 building block이 된다.
- 프로그램을 실행할 때, 사용자의 입장에서는 현재 실행되는 프로그램이 시스템에서 돌아가는 유일한 프로그램이고, 프로세서와 메모리를 독점하고 있는 것과 동일하게 보인다. 이는 프로세스가 있기 때문이다.
이 절에서는 OS가 프로세스를 어떻게 구현하는지보다는 logical control flow와 private address space의 두 추상화에 대해 설명한다. 각각은 우리 프로그램이 {프로세서, 메모리} 자원을 독점하고 있다는 착각을 제공해준다.
Logical Control Flow: PC 값의 수열을 의미
- 동시에 실행되는 각 프로세스가 일부 실행된 후 preempt됨(선점.?으로 번역되는데 적절한지 잘 모르겠다) -> 그 시간에 다른 프로세스가 실행될 수 있게 넘겨줌
- 일시정지되었다가 재개될 때, 프로그램의 메모리 위치나 레지스터의 상태가 복원됨
Concurrent Flows: 다른 logical flow와 실행시간이 겹치는 control flow
- X와 Y가 서로 concurrent하다 $\Leftrightarrow$ X의 시작시간이 Y의 시작시간과 끝 시간 사이에 있거나 그 반대
- multitasking(a.k.a. time slicing): 프로세스끼리 교대로 실행되는 것
- concurrent flow는 코어나 컴퓨터의 개수와는 무관
- parallel flow: concurrent flow의 proper subset으로, 두 flow가 서로 다른 코어나 컴퓨터에서 concurrent하게 실행될 경우를 의미
유저 모드와 커널 모드
- process라는 추상화를 제공하기 위해서는 애플리케이션이 실행할 수 있는 instruction의 범위를 제한하는 것이 필요 -> mode bit을 통해 구현
- mode bit이 1이면 프로세서는 커널 모드에 있는 것으로, privileged instruction의 실행이 가능해지고 모든 메모리 위치에 접근이 가능
- mode bit이 0이면 프로세서가 유저 모드에 있는 것으로, 커널 코드/데이터는 system call이라는 인터페이스로만 접근이 가능
- 애플리케이션을 실행하는 프로세스는 유저모드에서 시작함. 커널 모드로 전환하려면 exception이 일어나야 함
- exception handler는 커널 모드로 동작, 애플리케이션 프로그램으로 컨트롤을 반환할 때 유저 모드로 돌아감
- 리눅스에서는
/proc filesystem에 텍스트 파일들을 export함으로써 유저 프로그램이 커널 데이터구조에 접근할 수 있게 해줌
Context Switches
- Multitasking은 고수준의 exceptional control flow를 사용해 구현되는데, 이를 context switch라고 함
- context: 커널이 preempt된 프로세스를 재시작하기 위해서 필요한 상태들
- general-purpose/floating-point register들의 값, 유저/커널 스택, status registers, page table(주소 공간에 대한 정보), process table(현재 프로세스에 대한 정보)등의 커널 데이터구조
- scheduling: 커널이 현재 프로세스를 preempt하고, 이전에 preempt한 프로세스를 재시작하기 위한 결정 과정. 커널의 scheduler라는 코드에 의해 제어
- 커널이 새 프로세스를 스케줄링하면 현 프로세스는 preempt하고 context switch라는 메커니즘을 통해 새 프로세스에 컨트롤을 넘김
- context switch의 과정
- 현 프로세스의 context를 저장
- 이전에 preempt된 프로세스의 context를 불러와 복원
- restored process에 컨트롤을 넘김
- 커널이 시스템 콜을 실행중일 때에도 context switch가 일어날 수 있다
8.3. System Call Error Handling
system-level function에 에러가 발생하면,
- -1을 반환하고
- 전역변수
errno에 에러의 종류를 저장한다.
따라서 system-level function을 호출한 후에는 이를 항상 체크해줘야 하지만, 이는 매우 번거롭고 가독성을 떨어뜨린다. 따라서 CSAPP에서는 wrapper function들을 정의해 사용한다. 예시로 pid_t fork(void)에 대해서는 다음을 정의한다.
void unix_error(char * msg){
fprintf(stderr, “%s: %s\n”, msg, stderror(errno));
}
pid_t Fork(void){
pid_t pid;
if((pid = fork()) < 0){
unix_error(“Fork error”);
}
return pid;
}
따라서, fork()를 사용할 상황에 Fork()를 사용하면 의도한 효과를 가져오면서 에러 처리도 자동으로 되는 것이다. 앞으로 책에서는 csapp.h에 이들을 정의해두고 가져와 사용한다.
8.4. Process Control
Unix는 C 프로그램이 프로세스를 제어할 수 있도록 시스템 콜 형태로 다양한 인터페이스를 제공한다.
프로세스 ID 구하기
- 각 프로세스는 고유의 ID(PID)를 가진다. 이를 구하기 위한 함수들이 있다.
pid_t getpid(void): 현 프로세스의 PID를 반환pid_t getppid(void): 현 프로세스의 부모(parent) 프로세스의 PID를 반환pid_t는 sys/types.h에, 두 함수 자체는 unistd.h에 포함
프로세스 생성과 종료
- Running: CPU상에서 실행중이거나, 스케줄되어 실행되기 위해 대기중인 상태
-
Stopped: 프로세스가 중단된 상태
SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU 등 시그널에 의해 발생- 중단된 후 다시 스케줄되지 않지만
SIGCONT 시그널을 받으면 다시 시작된다
-
Terminated: 영구적인 stopped 상태
- terminate를 명령하는 시그널을 받거나,
main 함수가 반환했거나 exit()이 호출된 경우
프로세스의 생성과 종료에 관련된 system-level function은 다음이 있다.
exit(): int status를 입력받아 이를 status code로 하여 프로세스를 종료fork(): 자식(child) 프로세스를 생성
- 자식 프로세스는 부모 프로세스의 유저레벨 주소공간, 코드, 데이터, 힙, 공유 라이브러리와 유저 스택을 모두 복사해온다.
- 이를 “duplicate but separate”라는 phrase로 설명
- 그러나 PID는 다름
fork는 한 번 호출되고 두 번 반환(부모/자식 프로세스에서 한번씩)하는 특이한 특징이 있다
- 부모 프로세스에서는 생성된 자식의 PID를, 자식 프로세스에서는 0을 반환
fork를 사용하는 함수의 경우 프로세스 그래프를 사용하면 실행 순서의 partial ordering을 알아낼 수 있는데, 이를 위상정렬해 나올 수 있는 결과 중 무작위의 하나가 total ordering이 된다.
자식 프로세스의 회수
프로세스가 종료(terminate)된 후에도 커널은 이를 시스템에서 바로 지우지 않고 부모 프로세스가 이를 회수(reap)할 때까지 terminated 상태를 유지한다. 이렇게 종료되었지만 회수되지 않은 프로세스를 zombie라고 한다.
- 좀비를 가진 부모 프로세스가 terminate되면, 커널은 init 프로세스가 부모 프로세스의 "고아"들을 "입양"해준다. 그러나 오래 실행되는 shell이나 서버와 같은 프로세스는 zombie 자식들을 수동으로 회수해주는 것이 좋다.
- init 프로세스: PID 1, 시스템 startup 시 생성되어 절대 종료되지 않는 프로세스. 모든 프로세스의 조상
waitpid: 자식 프로세스가 stop이나 terminate되기를 기다릴 때 사용한다.
#include <unistd.h>
pid_t waitpid(pid_t pid, int *statusp, int options)
```
* default option(`options=0`)에서, `waitpid`는 waitset에 있는 자식 프로세스가 모두 종료될 때까지 실행을 멈추고 마지막으로 종료되는 자식의 PID를 반환
* `options`을 통해 행동을 바꿀 수 있음: 여러 개 적용시 `WNOHANG | WUNTRACED`와 같이 bitwise OR 연산을 적용
* `WNOHANG`: waitset 내에 종료된 자식이 하나도 없을 시 바로 반환시킴. 자식이 종료될 때까지 형 프로세스의 실행을 멈추지 않고 다른 작업을 하고 싶을 시 유용
* `WUNTRACED`: 종료(terminated)뿐만 아니라 정지(stopped)되기만 해도 반환
* `WCONTINUED`: waitset의 프로세스가 종료되거나 `SIGCONT`를 받아 정지 상태에서 풀려났을 때까지 calling process를 정지시킴
* `int *statusp`에 상태 정보가 인코딩되는데, `wait.h`에 정의된 매크로를 이용해 이를 해석 가능(p. 781 참고)
* calling process에 자식이 하나도 없을 시 -1을 반환하고 `errno`에 `ECHILD`를 기록
* `wait`: `waitpid`의 간략화된 버전으로 `wait(&status)`는 `waitpid(-1, &status, 0)`과 동일하다.
**프로세스를 Sleep시키기**
```c
#include <unistd.h>
unsigned int sleep(unsigned int secs);
int pause(void);
sleep: 정상적으로 반환 시 0을 반환하고, signal에 의해 중간에 멈출 시에는 남은 시간을 반환함pause: 프로세스에 의해 signal이 감지될 때까지 멈춤 상태로 대기
프로그램의 로딩과 실행
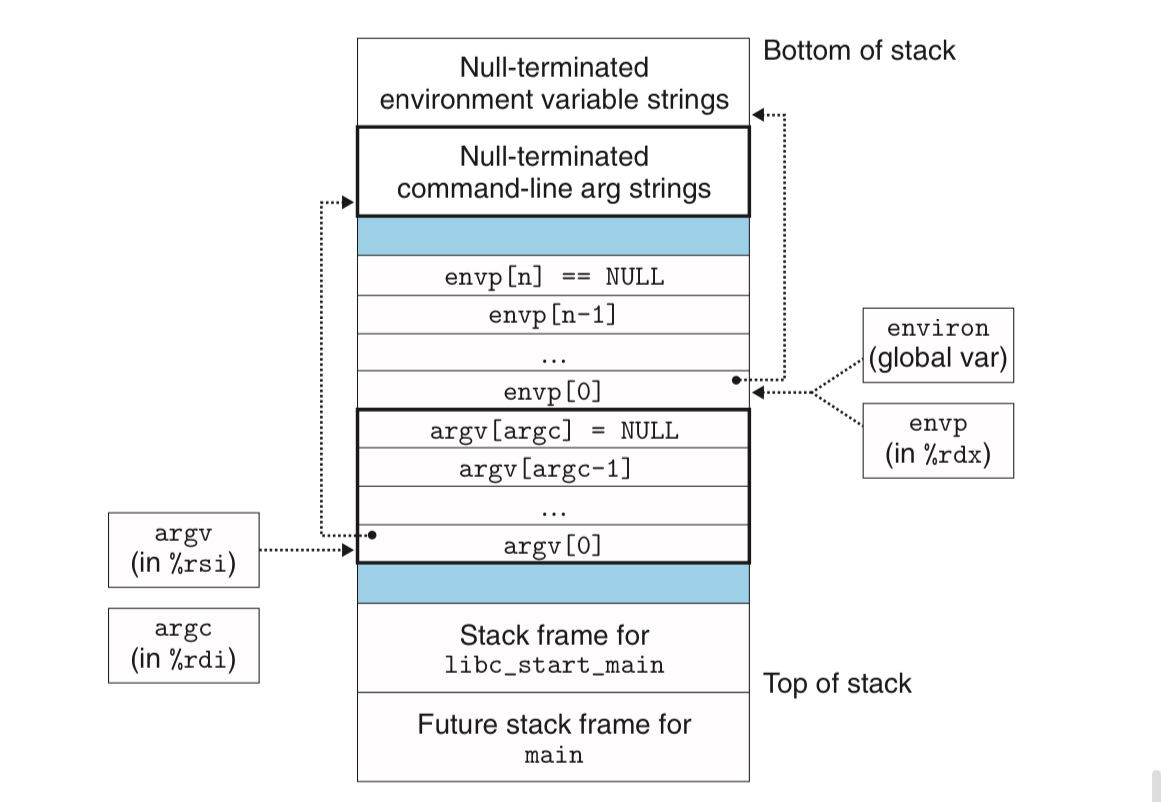
execve: 현재의 context에서 새로운 프로그램을 로드하고 실행시킴
filename을 찾지 못하는 등의 에러가 아닌 이상, 반환을 하지 않는 함수argv와 envp가 parameter로 같이 전달(각각 매개변수의 list와 환경변수의 list)- Section 7.9와 같이 startup code를 실행해, `int main(int argc, char argv[], char envp[]); 를 실행함
- 위 그림처럼 스택의 맨 밑(그림에서는 위)에 환경변수의 문자열(
"PWD=/usr/droh\0"와 같은 형식)들과 매개변수의 문자열들을 저장하고, 그 위에 이들의 포인터의 null-terminated 배열 *envp[]와 *argv[]가 차례대로 나열됨. 그 위에 libc_start_main의 stack frame이 위치
- 환경변수들을 처리하기 위한 함수로
getenv, setenv, unsetenv등이 있음
fork와 execve를 사용해 프로그램 실행하기 (pp. 790-792)
Unix 쉘과 웹 서버 등의 프로그램은 fork와 execve 등의 함수를 매우 자주 사용한다.
- Shell: 사용자를 위해서 다른 프로그램들을 실행시키는, application-level의 interactive한 프로그램
- 원조는
sh이지만 csh, tcsh, ksh, bash등이 파생
- 사용자의 입력을 받는 read step과 명령을 parse해 실행시키는 evaluate step으로 구분
- 코드를 간략하게 설명하자면, 쉘에 user program의 실행을 명령하면
fork로 자식 프로세스가 생성되고, 자식 프로세스에서 요청받은 프로그램을 실행함.
- 백그라운드 실행을 요청 받은 경우(
&) 바로 loop의 처음으로 돌아가고, 그렇지 않은 경우는 waitpid를 사용해 작업이 끝나기까지 기다린 후 반복
- 코드는 완벽하지 않음! 백그라운드에서 실행되는 자식 프로세스를 회수하려면 다음 절에 등장하는 signal의 개념이 필요
8.5. Signals
Linux signal: Exceptional control flow의 고수준, SW 버전
- 특정 타입의 이벤트가 시스템에 발생했음을 프로세스에게 알려주는 역할
- 유저에게 보이지 않는(user-invisible) HW exception들을 유저에게 노출시키는 역할도 수행
Signal Terminology
Sending a Signal
- 프로세스 그룹: 모든 프로세스는 process group ID를 가짐. 즉, 하나의 process group에 속함.
- process group ID는
getpgrp()로 알 수 있음
- 자식 프로세스는 기본적으로 부모 프로세스와 같은 그룹에 속하나,
setpgid를 사용해 변경 가능
/bin/kill: 다른 프로세스로 입의의 signal을 보낼 수 있음.
- e.g.
/bin/kill -9 15213: 9번 signal(SIGKILL)을 PID 15213에 해당하는 프로세스로 보내줄 것을 커널에 요청
- 그냥
kill이라고 하지 않는 이유: 특정 유닉스 쉘에서는 kill이 따로 존재하기 때문
- 키보드로 signal 보내기
- pipe를 이용해
ls | sort와 같이 명령을 입력하면 두 명령이 하나의 job으로 묶임.
*unix가 제공하는 추상화 중 하나
- 각 job마다 서로 다른 process group ID가 부여됨
Ctrl + C: 포그라운드 job에 SIGINT를 보냄 -> terminate시킴Ctrl + Z: 포그라운드 job에 SIGSTP를 보냄 -> suspend
kill function: 임의의 pid를 선택해 원하는 signal을 보낼 수 있음alarm function: 스스로에게 SIGALARM을 보냄(원하는 시간 secs초 후)
Receiving a Signal
Blocking & Unblocking Signals
Signal을 block하기 위한 방법
- 암시적: 현재 handler가 처리중인 것과 동일한 signal이 pending중이면 커널은 이를 막음
- 명시적:
sigprocmask를 이용해 block이 가능 (p. 801 참고)
Writing Signal Handlers
Signal handler를 작성하는 것은 다음의 여러 이유로 어려운 작업:
- main 프로그램과 concurrent하게 실행되면서 global variable을 공유함
- signal의 받기가 이루어지는 과정과 timing은 직관에서 벗어남
- 시스템마다 signal handling semantics가 각기 다름
Safe Signal Handling
- 최대한 단순하게(e.g. flag 변수 하나만 바꾸고 바로 return, 나머지 처리는 main에게 맡겨 flag를 주기적으로 체크하게 함)
- async-signal-safe한 함수만 사용
- local variable만 사용하거나, signal handler에 의해 interrupt되지 않는 함수를 의미
- output을 위해서는 유일하게
write()만이 사용가능
errno를 저장해두고 복원하기
- 많은 async-signal-safe 함수들은 반환시 에러와 함께 반환 시
errno를 설정함
- 이에 방해받지 않기 위해 handler 진입시 지역변수에
errno를 저장해두고 반환할 때 복원하는 방법 있음
- global data structure에 접근할 때에는 임시로 모든 signal을 block해두기
- global variable을
volatile으로 선언하기
- optimizing compiler가 변수가 handler에 의해 바뀔 수 있음을 모르고 해당 변수의 cache된 버전을 사용할 수 있기 때문
- flag 변수는
sig_atomic_t 타입으로 선언
- handler가 flag의 값을 바꾸고 main함수가 주기적으로 이를 체크해 처리하는 경우를 위해 C가 제공하는 데이터타입임
volatile sig_atomic_t flag;로 선언시, 해당 변수로의 읽기나 쓰기가 단일 instruction에 처리되어 중간에 끼어드는 것이 불가능하게 됨을 보장
Correct Signal Handling
동일 시그널이 처리중인 경우, 새로운 signal은 발생해도 queue되지 않음
- 즉 pending signal $k$가 존재한다는 사실은 $k$가 한번 이상 발생했다는 것을 알려줄 수 있을 뿐
- p.807~808의 예시: 자식 프로세스가 종료될 때 발생하는
SIGCHLD의 handler를 install함
- 이와 관련된 문제로 버그가 발생함! 핸들러가 발생할 때마다 최대한 많은 zombie들을 회수할 수 있도록 변형해주어야 옳음
Portable Signal Handling
시스템마다 signal-handling semantics가 달라서 발생하는 문제가 있음
- e.g. 초기 유닉스의 일부에서는 signal이 발생할 때마다 handler가 default로 초기화됨
- POSIX 표준의
sigaction 함수를 사용해 signal-handling semantics를 정확하게 정의 가능
- 위의 예시와 같은 경우는
sigaction 함수를 대신 호출해주는 wrapper function Signal()을 정의해서 사용할 수 있음
Synchronizing Flows to avoid Nasty Concurrency Bugs
-
concurrent flow들이 동일 메모리 위치를 참조하게 싶은 경우, 올바른 결과를 얻기 위해서는 flow들을 동기화하는 것이 중요한 문제

-
e.g. p. 813의 프로그램: 부모 프로세스가 자식 프로세스를 만든 후 다시 재개되기도 전에 자식이 terminate된다면 문제가 생김
- 부모 프로세스가 재개되면서
SIGCHLD handler를 실행한다면 부모 프로세스는 addjob()을 하기도 전에 deletejob()부터 수행하게 됨
- 이러한 상황을 race라고 하며, 고전적인 동기화 문제 중 하나
addjob()과 deletejob()의 실행 순서 사이에 race가 있다고 할 수 있으며, addjob()이 race에서 이겨야만 올바른 결과를 얻게 됨- p. 815에서는
fork()를 실행하기 전에 SIGCHLD를 막고(block) child process에서 다시 해제함으로써 오류를 해결함
Explicitly Waiting for Signal
- 특정 signal을 받기를 기다려야 하는 경우
- 무한루프를 돌면서 체크하는 것도 가능하나 비효율적(p. 816)
sigsuspend(const sigset_t *mask): 일시적으로 blocked signal set을 mask로 바꾼 후, handler를 호출하거나 terminate하는 signal을 받을 때까지 프로세스를 멈춤
- 마스크 설정 ->
pause() -> mask 복원의 과정을 atomic하게 옮겨놓은 것과 같음
- 이를 사용해 수정된 코드: p.818
8.6. Nonlocal Jumps
Nonlocal jump는 C에서 제공하는 유저레벨의 exceptional control flow로, setjmp와 longjmp의 두 함수를 사용한다.(`setjmp.h에 위치)
setjmp(jmp_buf env): buffer env에 calling environment(스택 포인터, PC, general-purpose register 등)를 저장함longjmp(jmp_buf env, int retval): 매개변수 env로부터 calling environment를 복원해와서, 가장 최근에 실행된 setjmp의 위치로 jump함
즉, setjmp는 호출은 한번 되는데 반환은 여러 번(호출 당시에 한번, jump될 때마다 한 번씩) 되는 함수이다.
Nonlocal jump의 일반적인 활용은 다음이 있다:
- deeply nested function call으로부터 즉각적인 탈출이 가능하다. (p. 820)
- signal handler가 return하지 않고 다른 code location으로 갈 수 있도록 해준다.