필자가 Princeton University가 Coursera에서 제공하는 Computer Architecture (Instructor: David Wentzlaff)를 듣고 일부를 요약해 정리한 글입니다.

캐시의 최적화
캐시를 디자인할 때는 여러 가지 고려할 사항들이 있다. 링크에서 다룬 것처럼 용도에 따라 캐시의 associativity와 block size 등을 조절해야 하며 write-back과 write-through, write-allocate와 no-write-allocate 중 어떤 것을 선택해야 할 지 등 또한 고려하여야 한다. 이 글에서는 캐시의 성능을 더욱 극대화하기 위해 사용되는 여러 최적화 방법들을 소개한다.
캐시의 평균 접근 시간은
Hit Time + Miss Rate $\times $ Miss Penalty
로 표현된다. 즉 hit time, miss rate, 그리고 miss penalty 각각을 줄임으로써 캐시의 성능을 향상시킬 수 있다.
여기서 캐시의 miss는 세 가지로 나뉠 수 있는데(Three C's of Cache), 다음과 같다.
- Compulsory Miss: 프로그램이 처음 시작할 때 캐시가 비어있기 때문에 어쩔 수 없이 발생하는 miss
- Capacity Miss: 캐시가 모든 프로그램 데이터를 담기에는 너무 작아서 생기는 miss
- Conflict Miss: fully associative cache가 아닌 경우에 cache collision이 발생하여 생기는 miss
1. Pipelining Cache Writes
가장 먼저 소개할 캐시 최적화 방법은 캐시 쓰기 단계를 파이프라이닝하여 write hit time을 줄이는 것이다. 캐시에 데이터를 쓸 때는
- tag의 match 여부와 valid bit를 확인해 캐시에 해당 데이터가 존재함을 확인한 후
- address로부터 index와 block offset을 뽑아내 쓰기를 하게 된다.
그런데 이 과정은 sequential해야 하므로, 일반적으로 두 사이클에 걸쳐서 수행된다. 이를 파이프라인화함으로써 실질적으로 한 사이클만을 사용하도록 할 수 있다.
이와 같은 최적화를 적용할 경우, write data는 캐시 바로 앞에 있는 delayed cache write buffer로 먼저 임시로 저장된다. 이때 데이터가 commit되었다고 할 수 있다. 이렇게 임시로 저장된 데이터는 바로 다음에 일어나는 store의 tag check시에 실제 캐시에 쓰이게 된다.

2. Write Buffers
Write buffer는 read miss penalty를 줄이기 위한 전략이다. L1 캐시에 Read miss가 날 경우, 높은 확률로 해당 데이터를 캐시에 불러오며 다른 데이터를 내쫓게(evict) 된다. 이때 evict된 데이터가 L2 캐시에 쓰기를 완료할 때까지는 너무 많은 시간이 걸리기 때문에, 이를 수행하는 writeback line에 write buffer를 하나 추가해 최적화를 수행할 수 있다.

이렇게 write buffer에 내용이 있는 상태에서 새로운 read가 발생하면 어떻게 할까? read할 주소가 L1 캐시에 있다면 그대로 읽어오면 되니 문제가 없다. 반면 read miss가 난 경우는 write buffer의 주소와 read miss의 주소가 같을 경우에만 (더 최신 버전인) write buffer의 내용을 읽어오면 된다.
3. Multilevel Caches
최근에 나오는 대부분의 시스템에서는 캐시가 여러 단계로 구성되어 있다. 메모리가 빠르면서 용량도 클 수는 없기 때문에, 단계별로 점점 크기가 커지도록 여러 캐시를 사용하는 것이다.
Multilevel cache를 다룰 때에는 miss rate의 보다 정확한 정의가 필요하다.
- local miss rate: 해당 캐시에 발생한 miss의 수를 해당 캐시로의 접근 수로 나눈 값
- global miss rate: 해당 캐시에 발생한 miss의 수를 전체 메모리 접근 수로 나눈 값
- misses per instruction: 해당 캐시에 발생한 miss의 수를 전체 instruction의 개수로 나눈 값
예를 들어서 L2 캐시의 miss rate를 이야기할 때, L1 hit가 나서 L2 cache에는 접근조차 하지 않은 memory access들은 global miss rate를 계산할 때는 고려해야 한다. 그러나 local miss rate를 계산할 때에는 고려하지 않는다.
L2 캐시가 추가로 도입되면 L1 캐시의 디자인에도 추가로 고려해야 할 사항들이 생긴다.
- L1 캐시의 크기를 줄여도 된다. L1 miss rate는 조금 높아질 수 있지만 그만큼 miss penalty와 hit time이 낮아지는 효과가 있기 때문이다.
- on-chip L2 캐시가 있다면, L1 캐시는 write-through로 만들 수 있게 된다. 만약 L2가 없는데 L1 캐시가 write-through라면 쓰기 발생 시마다 메인 메모리에 직접 쓰기를 하게 되므로 bandwidth가 매우 부족해진다. 따라서 L2가 없는 경우 어쩔 수 없이 L1 캐시를 (설계하기 상대적으로 복잡한) write-back으로 디자인하여야 한다. 그런데 L2 캐시를 on-chip, write-back으로 하여 도입한다면 이러한 write traffic을 모두 L2 캐시가 흡수하므로 chip 밖으로 가는(off-chip) bandwidth를 줄여준다. 따라서 L1 캐시를 설계하기 쉬운 write-through로 만들 수 있다.
- coherence issue를 간단하게 해결할 수 있다. 캐시의 coherence issue란 서로 다른 프로세서가 각각의 캐시를 가질 때, 각 프로세서의 캐시 내용이 서로 달라지는 문제를 말한다. 이를 위해서는 기존 파이프라인 외에 추가로 버스를 만들어 데이터를 교차검증해야 하는데, 코어간에 공유되는 L2 캐시가 있다면 이를 간단하게 해결할 수 있다.
- error recovery가 쉽다. 예를 들어, 방사선에 의한 soft error가 났다고 할때 write-back 방식의 L2 캐시는 항상 최신화된 상태를 유지할 수 있으므로, L1에 parity 비트를 두고 오염시에 L2에서 reload해오는 로직을 구현하면 된다.
Inclusion Policy
Multilevel cache를 도입할 시, inclusion policy를 어떻게 할지 설정할 수 있다.
- Inclusive cache: inner cache는 항상 outer cache가 가진 데이터의 부분집합이다. 즉, outer cache가 가지고 있는 주소의 데이터를 가지며 그 내용 또한 동일하다.
- Exclusive cache: inner cache가 outer cache에 없는 데이터를 가지는 것이 가능하다.
Inclusive cache의 경우 coherence를 검증할 때 outer cache만 검증하면 되어 편리하다는 장점이 있다. 반면 Exclusive cache는 구현이 복잡하지만, 유효 캐시 용량이 inclusive cache보다 크다는 장점이 있다. 예를 들어 L1 캐시에 있던 데이터가 evict된다면, 이 데이터는 L1 캐시에 들어갈 정도까지는 아니더라도 L2에 들어갈 정도의 중요성을 가진다고 판단할 수 있을 것이다. 따라서 exclusive cache의 경우 evict시마다 L1과 L2의 데이터를 서로 교환하는 식으로 구현하면 된다.
경험적으로는 캐시의 단계가 하나 내려갈 때마다 용량이 최소 8배가 되도록 하는 것이 좋다고 한다.
4. Victim Cache
Victim cache란 캐시에서 막 evict된 데이터들(victim)을 모아 저장해두는 캐시를 말한다.

Victim cache가 유용하게 쓰일 수 있는 상황을 가정해보자. 예를 들어 2-way 캐시에서 다음 코드를 실행한다고 해보자.
#define MEGA 1048576 // 2**20
int a[MEGA], b[MEGA], c[MEGA];
int i;
for(i = 0; i < 100; i++){
c[i] = a[i] + b[i];
}
위의 코드에서 a, b, c가 naturally aligned되어 있다면, 캐시에서 a[i], b[i], c[i]는 모두 같은 block index를 가지고 있을 것이므로 2-way 캐시는 이를 감당할 수 없고, loop를 돌 때마다 conflict miss가 발생한다. 이 경우, victim data를 수용할 수 있는 작은 fully associative cache를 하나 만들어주면 성능을 크게 향상시킬 수 있다.
5. Prefetching
Prefetching이란 미래의 instruction이나 data 접근을 예측하여 미리 캐시에 fetch해두는 테크닉이다. 이는 구현 방법에 따라 hardware prefetching, software prefetching, 그리고 mixed scheme으로 나뉠 수 있으며 그 적용대상에 따라 instruction과 data prefecthing으로 나뉠 수 있다.
Prefetching에서 가장 중요한 것은 예측의 정확도이다. 예측이 자주 빗나간다면 캐시의 유효 용량을 줄이는 효과를 내고, 이는 conflict miss의 확률을 높인다. 일반적으로 instruction prefetching은 상당히 높은 정확도를 달성할 수 있으나 data prefetching의 경우 높은 정확도를 내기 힘들다. 정확한 prefetching을 위해 고려할 사항은 다음 세 가지가 있다.
- Usefulness: hit이 많이 발생해야 한다.
- Timeliness: prefetch하여 데이터를 가져오는 시점이 너무 늦지도, 빠르지도 않아야 한다.
- Bandwidth polution: prefetch된 데이터를 사용하지 않는다면 bandwidth만 낭비하는 결과를 낳게 된다.
Hardware Instruction Prefetching
말 그대로 하드웨어적인 방법을 사용해서 i-캐시에 대한 prefetching을 수행하는 기법들이다. 여기에서는 Alpha AXP 21064 프로세서에서 적용된 테크닉을 살펴본다. 이 프로세서에서는 instruction fetch시 miss가 발생하면 요청한 블록의 바로 다음 블록을 함께 fetch하여 stream buffer라는 저장소에 저장해둔다.
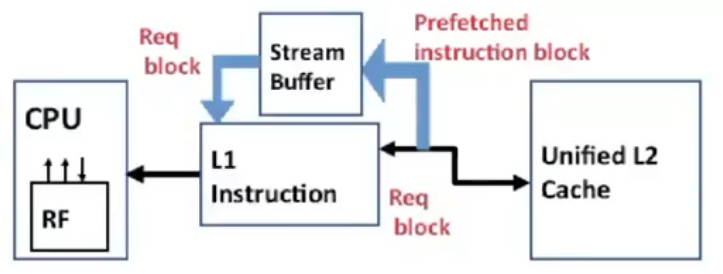
다음 번에 instruction fetch를 할 때 L1 i-캐시에서 miss가 난다면, stream buffer를 fetch하여 해당 데이터가 있는지 살펴본다. 만약 있다면 stream buffer의 block을 캐시로 가져오고, 그 다음 block을 stream buffer에 다시 채워 넣는다.
Hardware Data Prefetching
하드웨어적 기법으로 d-캐시에 적용할 수 있는 prefetching 기법이다. 상술했듯이 d-캐시의 경우 다음에 접근될 데이터가 어떤 것인지 예측하기가 비교적 어렵다. 따라서 아래와 같은 다양한 휴리스틱들이 사용된다.
- Prefetch-on-miss: 위의 instruction prefetching과 유사하게 block $b$를 접근했다 miss가 나면 $b+1$을 prefetch하는 방법이다.
- One block lookahead(OBL) scheme: $b$가 접근될 때 $b+1$을 prefetching하는 방법으로, $b+1, b+2, \cdots b+N$을 prefetching하도록 $N$-Block Lookahead로 확장이 가능하다.
- Strided prefetch: 접근된 블록의 번호에서 등차수열을 감지하여 $b, b+N, b+2N$이 순서대로 접근될 시 $b+3N$을 자동으로 prefetch하도록 한다.
Software Prefetching
컴파일러나 프로그래머의 수준에서 prefetching을 명시적으로 알려주어 캐시 접근 성능을 개선할 수 있다.
for(i = 0; i < N; i++){
prefetch(&a[i+1]);
prefetch(&b[i+1]);
SUM = SUM + a[i] * b[i];
}
위의 예시 코드에서는 매 iteration에서 그 다음 iteration에서 사용될 a[i+1]와 b[i+1]에 존재하는 데이터를 prefetching해온다. 이때 prefetch는 캐시 line을 chip 안으로 들여오는 load역할을 하게 하거나, off-chip bandwidth를 절약하기 위해 L2 캐시에 있는 경우에만 L1으로 들여오는 역할을 하도록 만들 수도 있다. 이런 경우 HW-SW hybrid approach라고 할 수 있을 것이다.
SW prefetching의 경우 특히 예측가능성보다도 prefetching이 일어나는 시점이 중요하게 작용한다. 위의 코드 예제에서도 로딩이 되는데 필요한 시간이 얼마나 긴지에 따라 매 i번 loop에서 a[i+1]이 아닌 a[i+2], a[i+3]의 데이터를 prefetch하는게 더 효과적일 수도 있는 것이다. prefetch가 너무 늦으면 해당 데이터가 필요한 시점에 사용이 불가능하고, 너무 빠르다면 캐시 데이터의 pollution을 야기할 수 있다. 따라서 데이터가 L1 캐시까지 도달하는 데 걸리는 시간을 계산하여 적절한 상수 P를 계산한 후 prefetch(&a[i+P])를 실시하는 식으로 최적화가 필요하다.
6. Multiporting and Banking
슈퍼스칼라 프로세서 등에서 여러 메모리 연산을 한꺼번에 처리할 수 있도록 하려면 (즉 메모리 연산의 throughput을 증가시키려면) 캐시에 입출력 포트가 여러 개여야만 한다. 이를 multiported cache라고 하는데, true multiported cache의 경우 구현해야 할 로직의 양이 매우 많아지고 이에 따라 hit time이 증가하는 등 도입시의 cost가 크다.
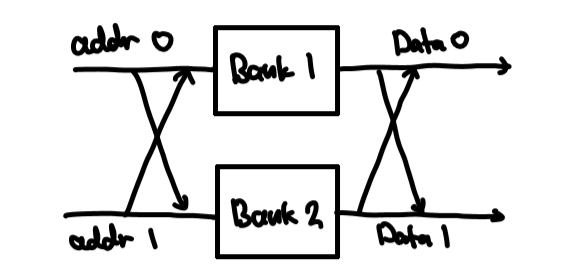
따라서 많은 경우 banked cache를 구현하여 사용한다. banked cache의 경우 외부와의 인터페이스는 true multiported cache와 동일하지만, 내부 구조를 뜯어보면 여러 개의 bank로 구성되어 있다. 각각의 bank는 독립적인 캐시와 유사하게 동작하는데, 주소의 일부분을 bank index로 사용하여 interleaving시켜 전체 캐시를 구성한다. 예를 들어, 주소의 마지막 bit가 0이면 bank 1, 1이면 bank2에 접근하기로 약속하고 주소의 나머지 비트들을 사용해 각 bank에 접근할 수 있다.
위의 그림에서, addr0과 addr1에 동시에 주소가 들어온 상황을 가정해보자. 만약 두 주소가 서로 다른 bank에 매핑된다면, 두 주소를 그대로 사용하거나 서로 swap하여 해당되는 bank에 접근하도록 한다. 두 주소가 같은 bank에 매핑되는 경우 문제가 생기는데, 이를 bank conflict라고 한다. Conflict가 발생한다면 stalling을 통해 두 메모리 접근 연산 중 하나는 다음 사이클로 미루어야 하나, 일반적으로는 포트의 개수보다 bank의 개수를 훨씬 크게 설정함으로써 그 빈도를 줄일 수 있다.
Banked cache의 효율을 극대화하기 위해서는 각 bank가 고르게 접근되어야 한다. 이를 위해 bank index는 주소의 mid나 lower order에 해당하는 비트들로 사용하는 것이 좋다. Bank index가 MSB에 가깝다면, 하나의 프로그램에서는 대부분의 메모리 연산이 하나의 bank에 매핑될 것이기 때문이다. 또한 memory alignment이 적용된 프로그램이라면 대부분의 데이터 접근이 4나 8과 같은 숫자의 배수가 되기 때문에 LSB에 너무 가까운 비트를 사용해서도 안된다.
7. Software Memory Optimization
위에서 살펴본 방법들이 캐시의 최적화를 위해 하드웨어 구조 자체를 바꾸는 기법들이었다면, 컴파일러나 프로그래머가 직접 캐시 친화적인 코드를 작성하는 식으로 소프트웨어 단계에서 최적화를 할 수도 있다. 여러 메모리 접근을 그룹화시켜서 spatial locality를 높이거나, 그 순서를 바꾸어 temporal locality를 높이는 것이다.
Loop Interchange
for(j = 0; j < N; j++){
for(i = 0; i < M; i++){
x[i][j] = 2 * x[i][j];
}
}
위와 같은 코드는 캐시를 충분히 활용하지 못하는 코드이다. x[i][j]로의 접근은 보통 x[N*i+j]에 접근하는 것과 같기 때문에, i에 대한 반복문이 더 바깥에 있는 위와 같은 코드는 spatial locality가 매우 낮다. 따라서 두 반복문을 서로 바꾸어주어 성능을 향상할 수 있다.
for(i = 0; i < M; i++){
for(j = 0; j < N; j++){
x[i][j] = 2 * x[i][j];
}
}
Loop Fusion
for(i = 0; i < N; i++)
a[i] = b[i] * c[i];
for(i = 0; i < N; i++)
d[i] = a[i] * c[i];
위의 코드를 보자. 위 코드는 두 배열 b[i]와 c[i]를 점별곱셈한 배열 a[i]를 계산한 후, 이를 다시 활용하여 d[i]를 계산하고 있다.
for(i = 0; i < N; i++){
a[i] = b[i] * c[i];
d[i] = a[i] * c[i];
}
위와 같이 두 반복문을 서로 합쳐주면, 각각의 i에 대해서 a[i]와 c[i]가 모두 캐시에 올라와 있는 상태에서 둘을 곱하므로 temporal locality가 향상되고, 메모리 접근 시간을 아낄 수 있다.
Example: Matrix Multiplication
두 $N\times N$ 행렬의 곱을 계산하는 코드를 생각해보자. 캐시를 고려하지 않은 naive한 코드는 다음과 같다.
for(i = 0; i < N; i++){
for(j = 0; j < N; j++){
r = 0;
for(k = 0; k < N; k++){
r = r + y[i][k] * z[k][j];
}
x[i][j] = r;
}
}
위의 코드는 캐시의 측면에서 매우 비효율적으로, 개선의 여지가 충분하다.
- 먼저
z[k][j]의 경우 k loop가 더 안쪽에 있으므로 N의 stride를 가지는 패턴으로 접근된다. 특히 N이 충분히 큰 경우, 데이터 하나를 접근하기 위해 매 번 cache block을 통째로 로딩해와야 한다.
y[i][k] 또한 N이 크다면 y[i] 전체가 하나의 캐시블록에 있지 않게 되고, 캐시에 여러 line으로 나뉘어 로딩된다.
이러한 문제점을 개선하여 캐시친화적으로 행렬 곱셈 코드를 재작성하면 다음과 같다.
for(jj = 0; jj < N; jj = jj + B){
for(kk = 0; kk < N; kk = kk + B){
for(i = 0; i < N; i++){
for(j = jj; j < min(jj + B, N); j++){
r = 0;
for(k = kk; k < min(kk + B, N); k++)
r = r + y[i][k] * z[k][j];
x[i][j] = x[i][j] + r;
}
}
}
}
위의 코드에서 안쪽 3개 loop를 보면, i가 가장 바깥에서 0에서 N-1까지 증가하고, j와 k는 한번에 B까지만 증가한다. 여기에서 B를 캐시 블록의 크기 이하로 설정한다. 이 경우 y[i][k]는 i가 고정된 상태로 k가 kk에서 kk+B까지
contiguous하게 접근하는 과정을 반복하게 되고, z[k][j]는 여전히 stride-$N$으로 접근되나 working set의 크기가 훨씬 작아지게 된다. 따라서 temporal/spatial locality가 훨씬 향상되고, 캐시에 친화적으로 프로그램을 실행할 수 있다.
8. Non-Blocking Caches
캐시의 데이터를 접근할 때 miss가 발생하면 해당 데이터를 더 낮은 단계의 캐시나 메인 메모리에서 로딩해와야 한다 (miss penalty). 그런데 이는 프로세서의 기준에서 보면 매우 긴 시간이 걸리는 작업이며, 그 동안은 다른 메모리 연산을 할 수 없어 시간이 낭비된다.
Non-blocking cache(또는 out-of-order memory system, lockup free cache)란 이렇게 miss를 처리하기 위해 낭비되는 시간에 뒤따르는 메모리 연산들을 처리할 수 있도록 해주는 캐시들을 말한다. Non-blocking에서 허용하는 케이스는 크게 두 가지가 있다.
- Hit-under-miss: Miss를 처리하는 동안에 hit인 메모리 접근을 먼저 실행시킬 수 있다.
- Miss-under-miss: Concurrent misses라고도 하며, miss를 처리하는 동안에 다른 miss를 동시에 처리한다.
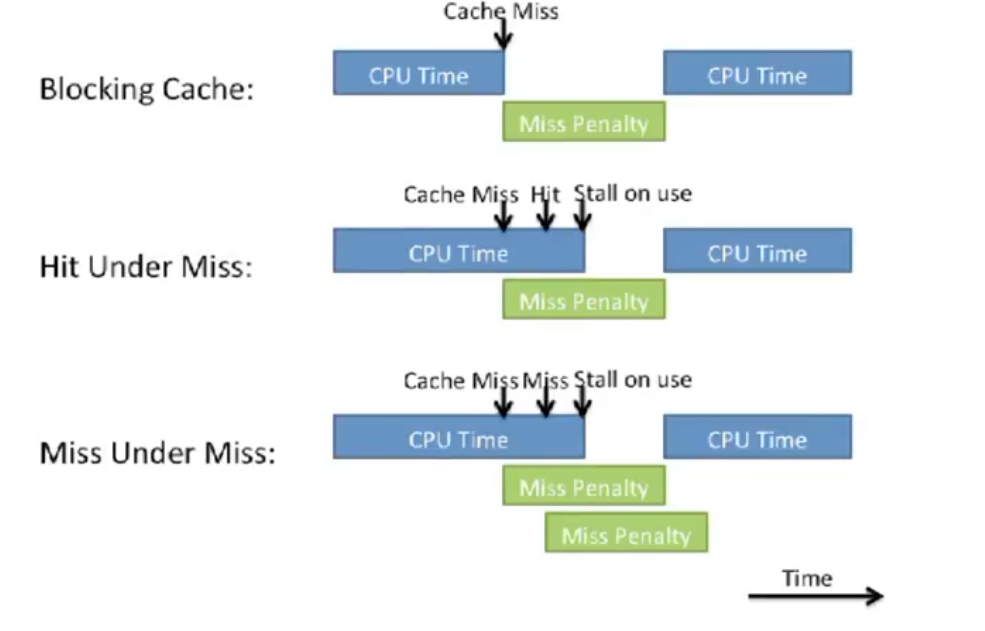
이렇게 non-blocking으로 메모리 접근을 허용하게 되면 몇 가지 해결해야 할 문제가 생긴다. 먼저 여러 miss에 대한 응답이 out-of-order로 올 수 있다. 각 data가 몇 번째 miss에 대한 응답인지를 잘 파악하여 필요한 위치에 배치하는 로직이 필요하다. 또한, 이미 miss가 일어나 miss penalty를 겪고 있는 주소로 다시 load/store를 하는 instruction이 있다면 이를 적절하게 처리해주어야 한다.
Nonblocking cache를 채택하는 시스템에서는 Miss Status Handle Register(MSHR) 또는 Miss Address File(MAF)이라고 불리는 자료구조를 도입하여 이러한 문제들을 해결한다. MSHR은 다음과 같은 세 개의 항목을 저장하는 associative table이다.
- Valid bit
- Block address: miss가 난 캐시 블록의 주소
- Issued: miss가 났다는 사실이 아래 단계의 캐시나 메인 메모리로 issue되었는가
MSHR은 Load/Store Entry와 함께 사용된다. Load/Store Entry는 다음과 같은 column들로 구성되어 있는 표로, MSHR entry의 번호로 associative search를 할 수 있도록 되어 있다.
- Valid bit
- MSHR Entry의 번호
- Type
- Offset: 캐시 블록 내에서의 주소 offset
- Destination: (load시) register, (store시) store buffer entry
Nonblocking Cache의 동작
위와 같은 자료구조를 활용하여, non-blocking cache는 miss penalty를 마친 데이터가 out-of-order로 돌아와도 상관이 없도록 처리한다.
먼저 Cache miss가 발생하면 캐시는 MSHR에 해당 주소가 있는지를 먼저 확인한다. 만약 있다면 현재 miss 처리중인 것이므로 해당 MSHR을 가리키는 새로운 load/store entry를 생성한다. MSHR에 해당 주소가 없다면 새로운 MSHR entry와 load/store entry를 생성한다. 만약 MSHR이나 load/store entry가 포화상태라면 stall한다.
Miss penalty를 마친 데이터가 메모리로부터 돌아온다면, 해당 데이터를 기다리고 있는 load/store entry가 어떤 것인지를 찾아서 이를 기다리는 destination(레지스터나 store buffer entry)으로 데이터를 전달해준다. 처리가 완료되면 MSHR entry를 할당해제해주어야 한다.
9. Critical Word First and Early Restart
캐시 miss가 났을 때, 일반적으로는 캐시 블록의 offset 0부터 B-1까지의 주소를 순서대로 로드한다. 이를 개선하여 성능을 소폭 향상시킬 수 있다.
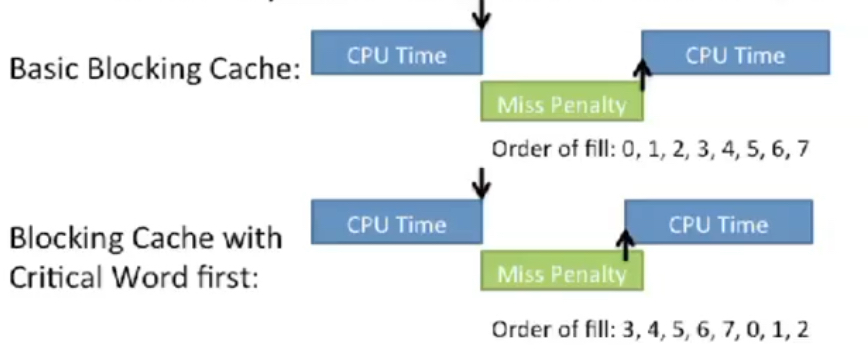
Critical word first는 원하는 데이터 주소를 먼저 가져오도록 캐시에서 데이터를 로드하는 순서를 rotate시키는 방법이다. 그림은 프로세서가 캐시에 offset 3에 있는 데이터를 요청한 상황으로, 캐시는 그 하위의 캐시로부터 캐시라인을 가져올 때 3의 데이터부터 채워넣는다. 이를 통해 캐시라인 전체가 채워지기 전에도 프로세서에 요청된 데이터를 반환할 수 있다.
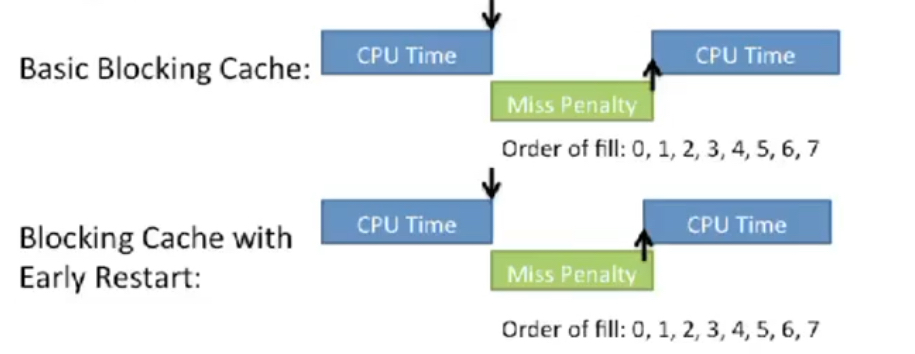
Early restart의 경우, 캐시는 데이터를 순서대로 채워넣지만 원하는 word가 반환되는 즉시 프로세서 실행을 재개한다.